模型融合与聚合贯穿于机器学习领域,犹如璀璨繁星熠熠生辉,勾勒出精确且富于韵律感的全貌。各类模型在此相互作用,以实现更精深的预测效果。本文旨在深入解析这两大技术如何助力预测精度的提高。
模型融合:不同模型的华丽组合
模型集成之道贵在运用多样模型,充分挖掘它们的潜在优势。其发挥恰如舞者们于舞台上的默契共舞,彼此相得益彰,展现出无与伦比的美妙篇章。
仿真模型融合的成败取决于对多种模式的透彻理解及和谐运用。舞者适配每个模型特性能达至最好成效,以此类比,特殊算法驱动,多元模型可达到互补强化与高效学习,从而构建更为强大的整合体。
def simple_average(predictions):
return sum(predictions) / len(predictions)
模型聚合:策略性的预测结果组合
def weighted_average(predictions, weights):
weighted_sum = sum(p * w for p, w in zip(predictions, weights))
return weighted_sum / sum(weights)
模型集成的目的在于系统性构建与优化模型体系,并非简单地将多模型成果汇总叠加。关键在于运用科学方法提升整体精准度。犹如舞会上舞者各自展现个性风采,最终仍需整体协调,方能呈现精彩演出。
在融合模型技术领域中,简洁高效的简单平均法备受瞩目。其主要理念是整合并修正各种模型预测的结果,再根据样本人数的总和进行统一调整,以提升拟合度,从而对全局观测量的发展变化做出更精确的描述。虽然该方法看似简单,但在诸多实践案例中却表现出了卓越的性能优势。
投票法:分类问题的常用策略
from collections import Counter
def majority_vote(predictions):
votes = Counter(predictions)
majority = votes.most_common(1)[0][0]
return majority
在分类问题处理过程中,投票法是最为广泛采用和实用的模型整合策略之一。这种方法犹如仲裁员,各预测得以借助其各自的打分权重得到支撑,优胜者即可获得最高精度的判断。
投票法关键在于适应不同场景并合理配置多种模型的比例,这就如同评审员在评判参赛选手时必须全方位思考各个层面的问题同时,也需要在个别模型表现不佳时及时调整权重,从而提升整体预测的精准性。
堆叠:更复杂的模型聚合方法
“叠加法”,运用多元化模型综合输出,精准构建模型以提高精度。此过程如精妙编排的舞蹈节目,每位舞者各自展现优美风姿,最后齐聚新舞台呈现出色技艺合奏。
栈叠法,一种广泛应用的机器学习手段,可融合多种模型的优势,以提升预测精确度。该方法的关键点在于将元模型作为核心,并整合反馈信息来增强性能。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator, TransformerMixin, ClassifierMixin
from sklearn.base import clone
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
import numpy as np
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义Stacking类
class StackingClassifier(BaseEstimator, ClassifierMixin, TransformerMixin):
def __init__(self, base_classifiers, meta_classifier):
self.base_classifiers = base_classifiers
self.meta_classifier = meta_classifier
def fit(self, X, y):
# 克隆基模型,避免修改原始模型
self.clones_ = [clone(clf) for clf in self.base_classifiers]
# 训练基模型
for clf in self.clones_:
clf.fit(X, y)
# 创建用于训练元模型的数据集
meta_features = np.column_stack([clf.predict(X) for clf in self.clones_])
# 训练元模型
self.meta_classifier_ = clone(self.meta_classifier).fit(meta_features, y)
return self
def predict(self, X):
# 基模型的预测结果
meta_features = np.column_stack([clf.predict(X) for clf in self.clones_])
# 元模型的最终预测
return self.meta_classifier_.predict(meta_features)
# 实例化基模型和元模型
base_classifiers = [DecisionTreeClassifier(), KNeighborsClassifier(), SVC(probability=True)]
meta_classifier = LogisticRegression()
# 创建Stacking分类器
stacking_clf = StackingClassifier(base_classifiers=base_classifiers, meta_classifier=meta_classifier)
# 训练Stacking分类器
stacking_clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = stacking_clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Stacking Classifier Accuracy: {accuracy:.2f}")
提升法:迭代技术的威力
提升法属于逐层迭代优化方式,通过不断修正数据权值优化模型训练过程。在这个方法中,每次递归学习重点关注前几层错误分类的样例,从而加强各机器学习器之间的内在关联性,最终提升整体模型精度。
在机器学习领域,增强学习,亦称”Boosting”,被誉为提升算法的引领者。其独特之处在于,通过井然有序地搭建多重模型,巧妙地克服了单个模型可能产生的局限性,由此达成更为准确和全面的预测效果。
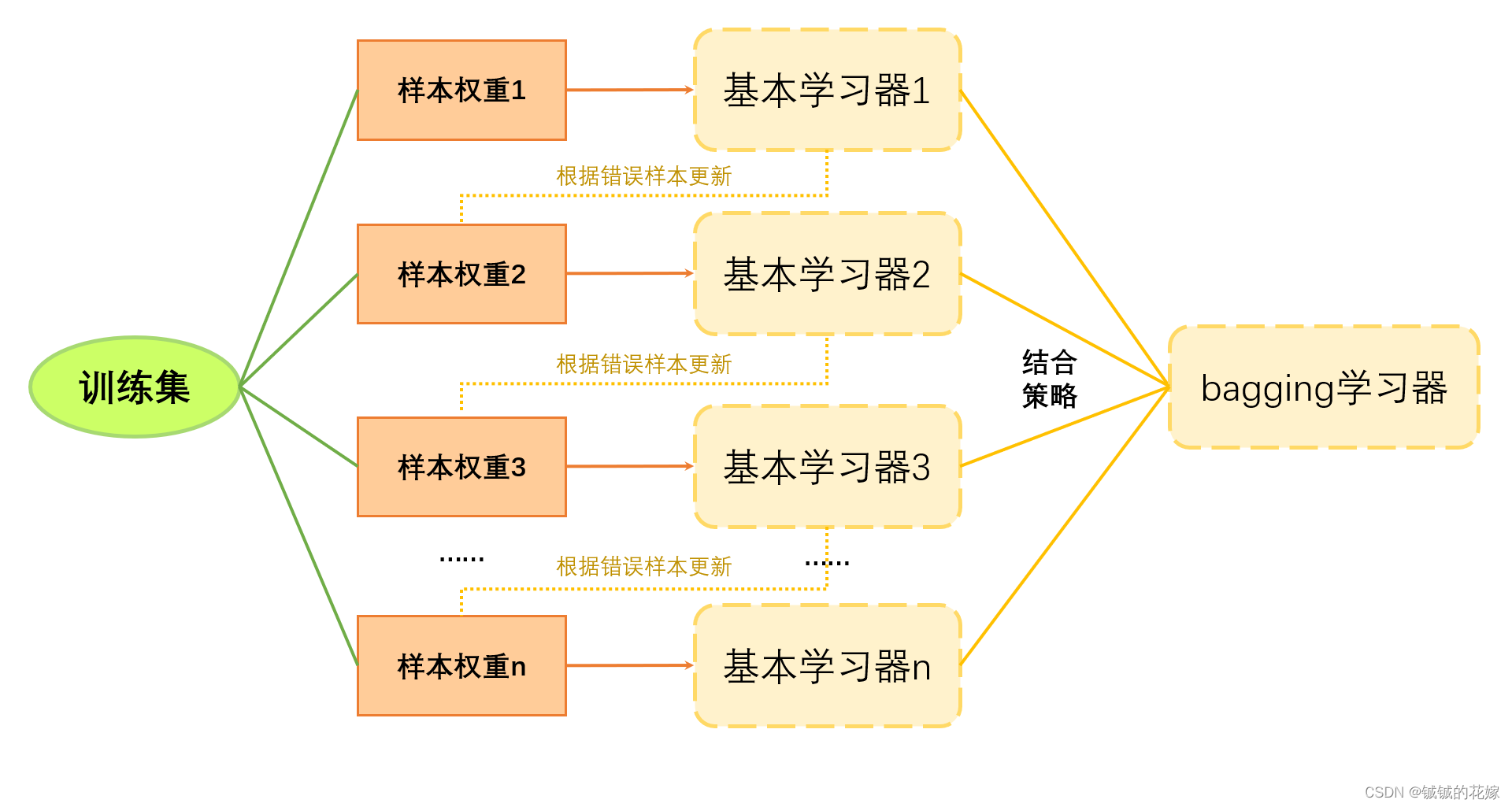
AdaBoost:提升法的经典实现
Adaboost作为独特而优秀的机器学习提升算法,巧妙地借助决策树这一强劲工具,有效应对并解决复杂的分类问题。经训练后,运用对测试样本进行严谨预测,可精确呈现模型的卓越性能与表现。
AdaBoost的关键在于如何调整每个模型的权重。
模型融合与聚合的应用领域
众多机器学习运用如图像识别、自然语言处理及推荐系统,均通过模型整合和集成技术提升精度与效率。
在图像分析领域,多元数据的融合能显性的提高识别精确度。类似地,这一技术也能够在自然语言处理过程中,提取更深入的语义信息;同样,在进行个性化推荐时,可以为用户提供精准的内容推荐。
总结与展望
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
data = load_breast_cancer()
X, y = data.data, data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化基学习器
base_estimator = DecisionTreeClassifier(max_depth=1)
# 初始化AdaBoost分类器
ada_boost_clf = AdaBoostClassifier(base_estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42)
# 训练模型
ada_boost_clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = ada_boost_clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"AdaBoost Classifier Accuracy: {accuracy:.2f}")
在机器学习领域,模型融合与聚合作为提升预测精度的关键技术具有无可替代的价值。该技术在诸多行业的实践中展现出卓越性能,进而揭示了精准预测背后更深层次的原理。
在把握机遇迎接挑战的当下时代,模式集成和聚合的应用将推动我们取得各行业更卓越的成就。预计未来,先进科技的日益精进必将助力造就更为令人瞩目的创新硕果。
尊敬的各位专家,诚挚邀请您参与讨论:关于未来模型融合与聚合技术的发展方向,您有何高见?欢迎在评论区分享,共同探讨这一重要话题。期待大家积极互动,感谢配合与支持!