数据清洗在数据分析过程中扮演着关键角色,采用恰当的方法和巧妙运用公式能显著提高数据整理效率。接下来,我将详细阐述不同字符处理公式的具体操作步骤及运用技巧。
固定位置字符提取
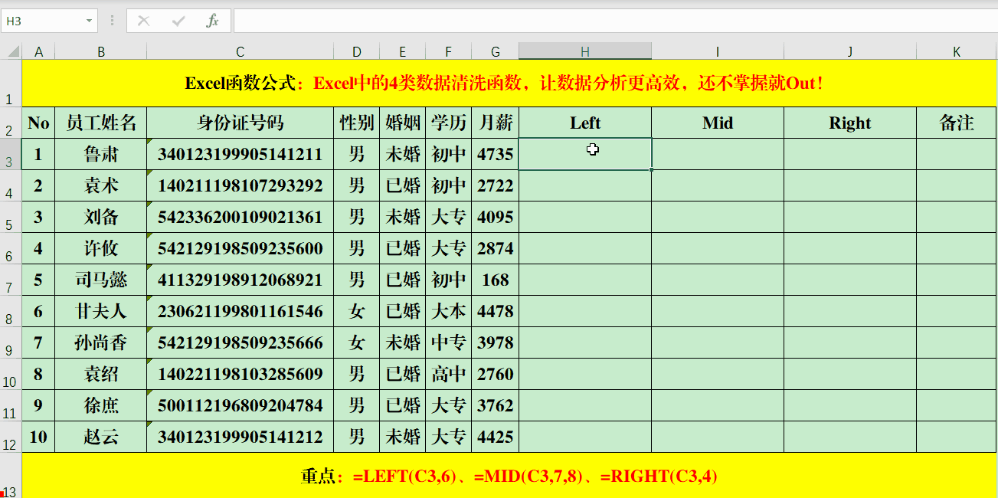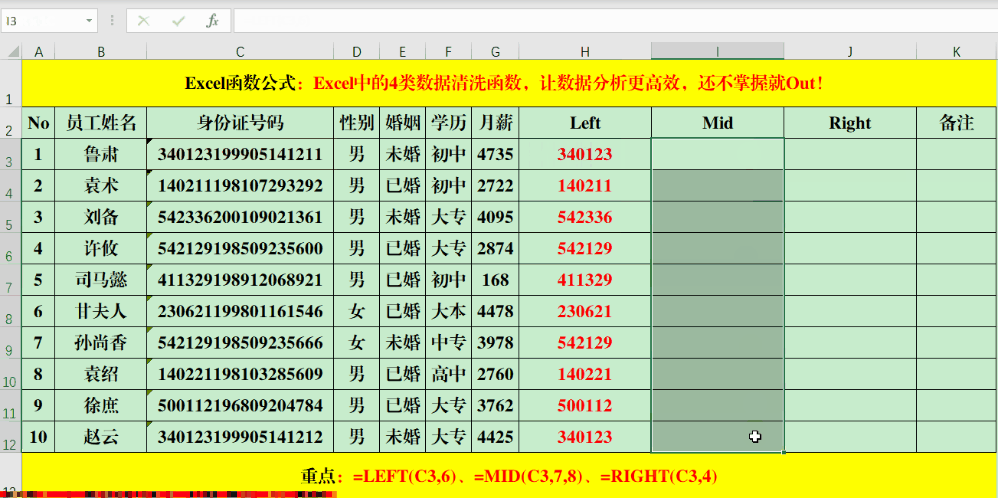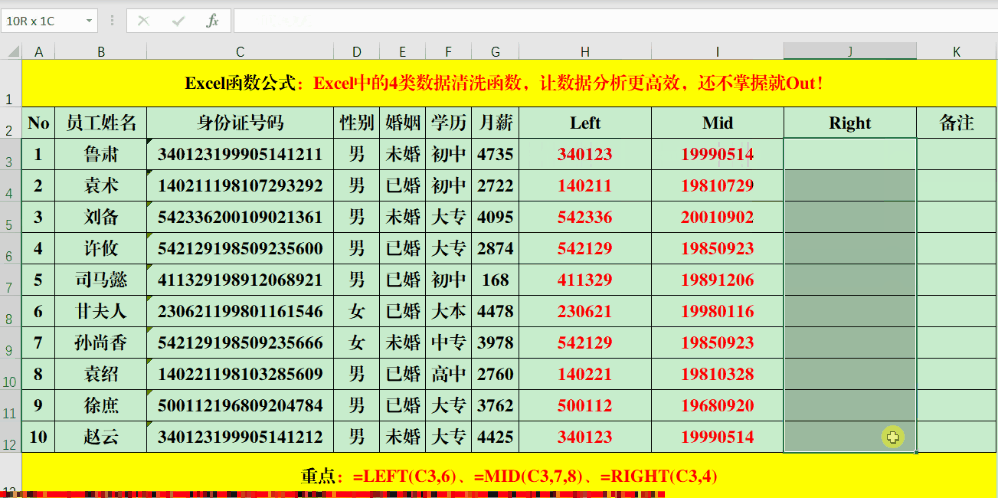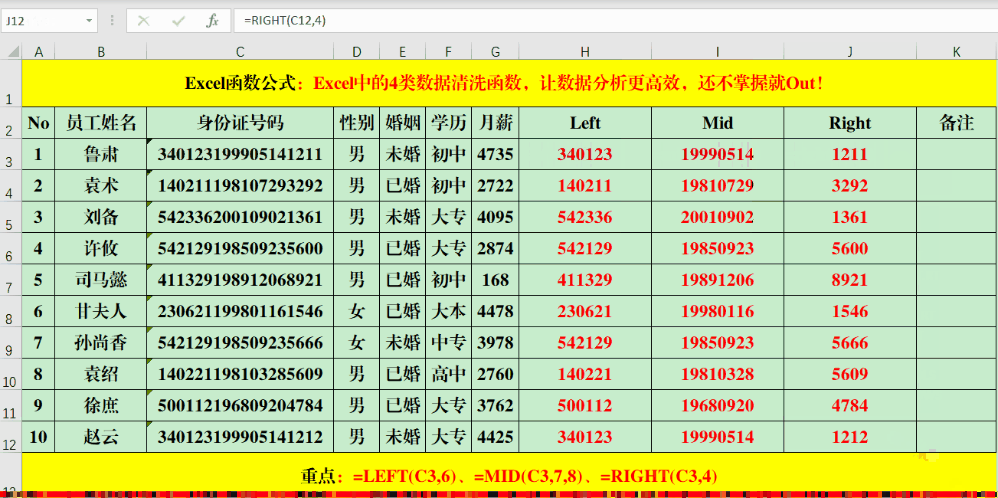
LEFT、Mid、Right这三个公式让提取特定单元格的数值变得轻松。比如,在目标单元格输入公式“=LEFT(C3,6)”可以获取C3单元格左边六个字符,“=MID(C3,7,8)”则可获取C3单元格从第七个字符开始的八个字符,“=RIGHT(C3,4)”则是获取C3单元格右边四个字符。处理规律性文本时,这一步骤既简单又迅速,能迅速获取所需特定区域的数据。
在日常工作里,若遇到如身份证号、产品序列号等格式统一的文本,这些公式便能发挥其作用。它们可以准确提取特定位置的字符,这对数据的分类和筛选大有裨益。因此,工作效率能得到明显提高。
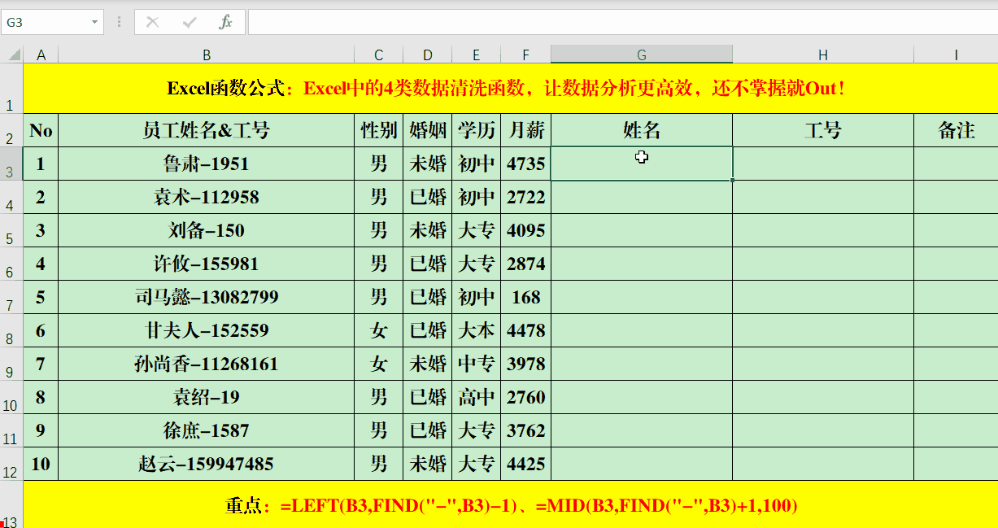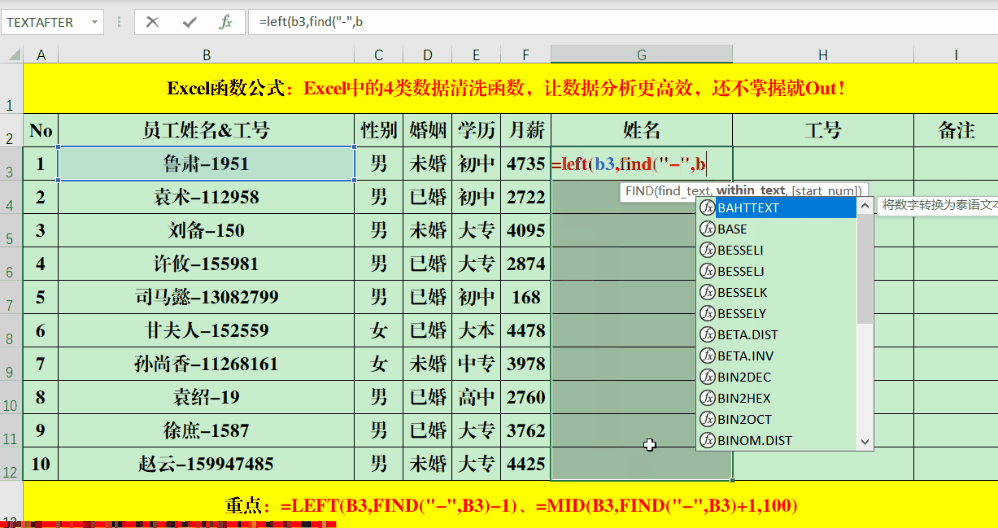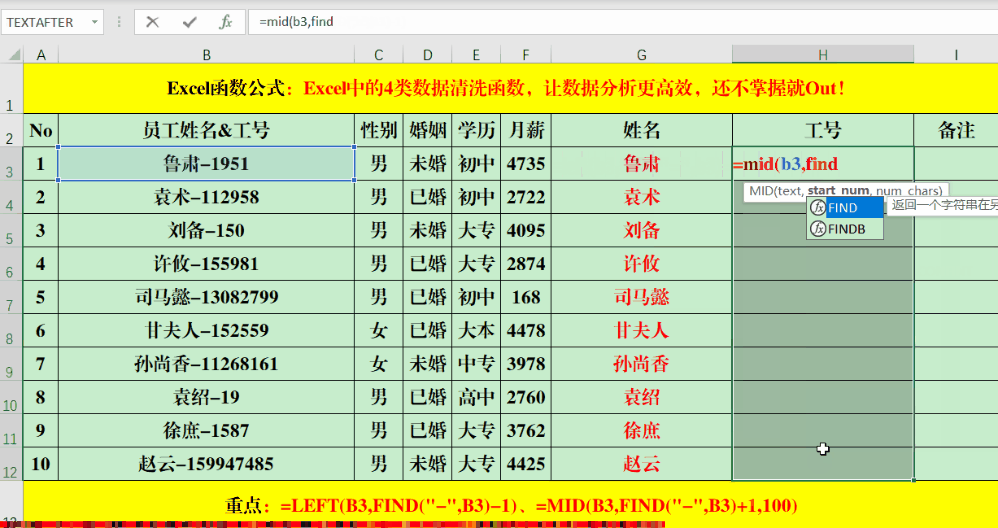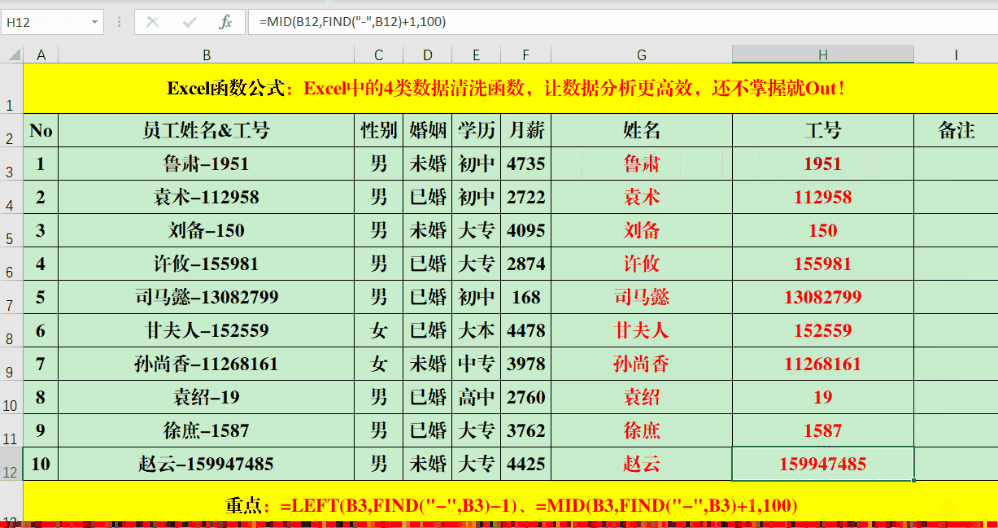
Find函数不仅能读取特定位置的数字,也能处理位置变动的情况。只需在目标单元格输入特定的公式,例如“=LEFT(B3,FIND(“-“,B3)-1)”或是“=mid(B3,FIND(“-“,B3)+1,100)”,就可以根据特定条件提取所需的数据。
公式里,负一和正一的符号是用来对数据进行微调的,得根据具体情况来变动。还有,那个100只是个大概数,主要是为了确保它比目标字段的长度要多。所以,我们要根据实际提取的字符数来对100这个数进行适当的修改。
字符清除技巧
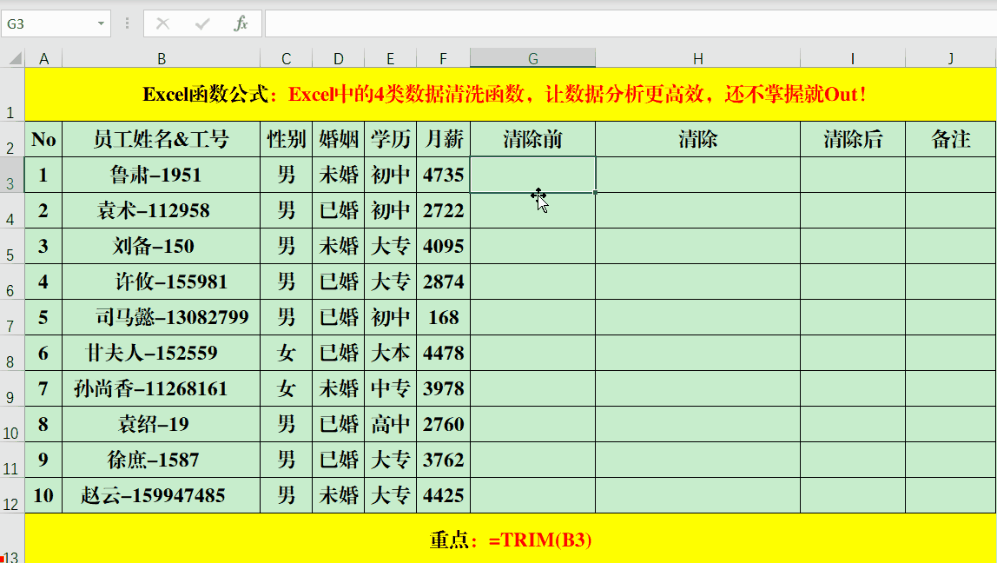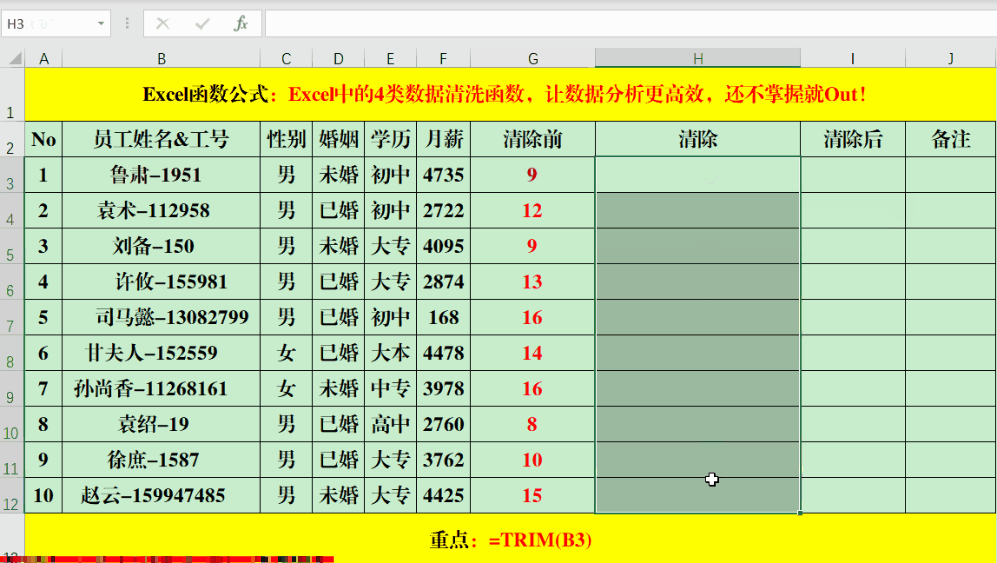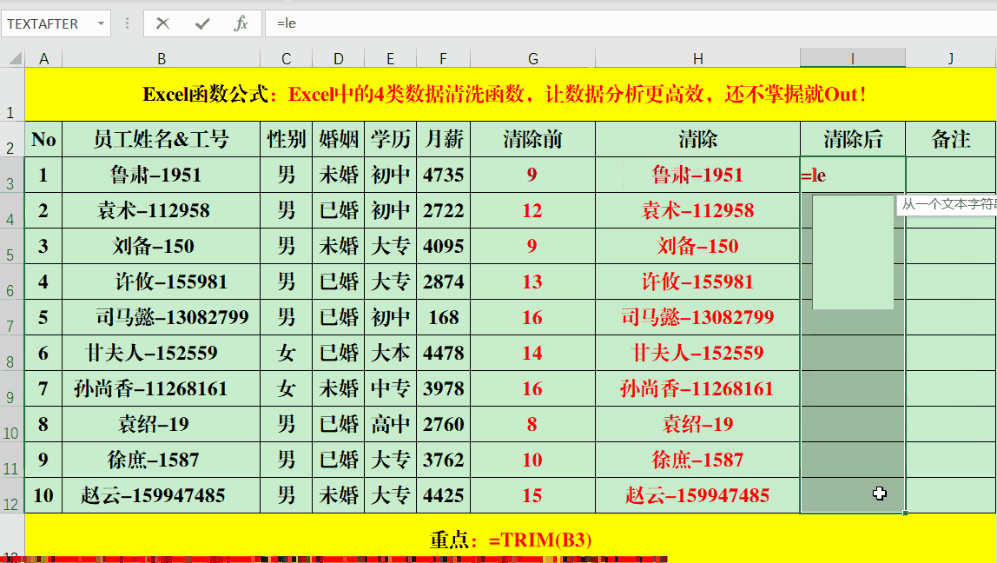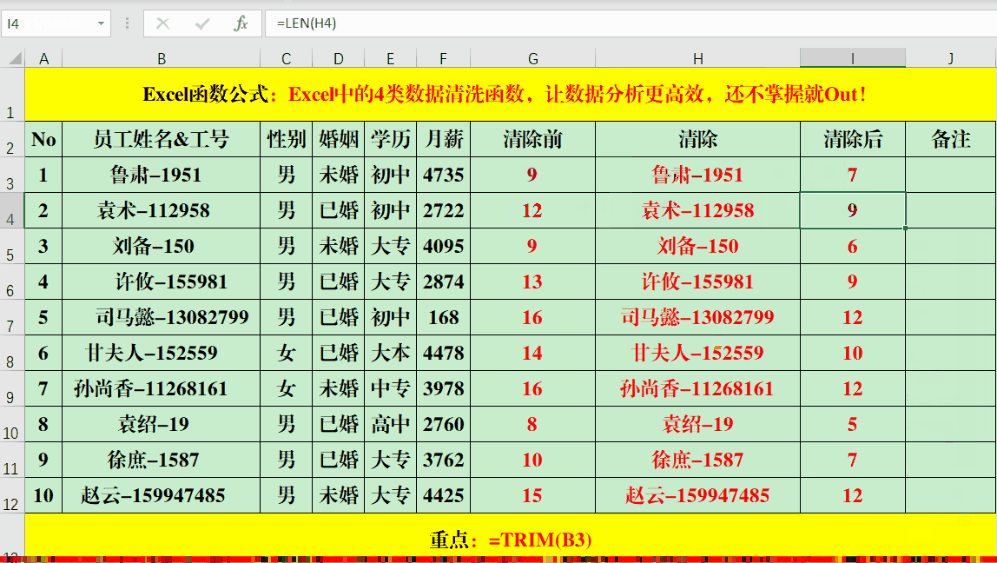
在目标单元格输入公式后,多余空白将从字符串中去除。为了便于观察变化,我们可以使用“Len”函数来比较处理前后的字符串长度。
若字符串内部有多余的空白字符,该公式将仅保留一个,其余将自动删除。在处理用户提交的文本资料或网页抓取的数据时,多余空格往往会影响数据准确性,此时运用 TRIM 函数便能有效解决问题。
部分字符串替换

此函数有替换指定文本段落的功能。使用时,需在公式中输入“=Replace(原文本,起始位置,字符数量,新文本)”这一格式。举例来说,若要在指定单元格内进行替换,可输入公式“=REPLACE(B3,FIND(“-“,B3),1,”*”)”。
操作文本时,若需对特定符号或词进行替换,可使用Replace功能,此功能可精确地在指定区域进行替换。此外,该操作既简单又快捷。
指定字符替换
Substitute函数可以用来把某个字符串中的特定字符替换成另一个字符。操作时,需要在单元格中输入一个公式:“=Substitute(源字符串,被替换字符,替换字符,替换顺序可选)”。如果不填写替换顺序,系统会自动把源字符串里第一个出现的被替换字符替换掉。
以“我爱我的祖国”为例,若我们将“替换序号”设为1,那么只会替换掉句子中第一个出现的“我”字。在日常生活和工作中,如果我们需要批量替换文本中的特定词汇,Substitute函数能够迅速找到并完成这一操作。

字符串合并方法
Concat、Phonetic、Textjoin这三个函数都可以用来连接字符串。使用Concat函数时,要注意输入格式,正确写法是“=Concat(字符串或单元格范围)”。比如,要合并B3到F3单元格区域的文本,就在单元格里输入“=CONCAT(B3:F3)”。
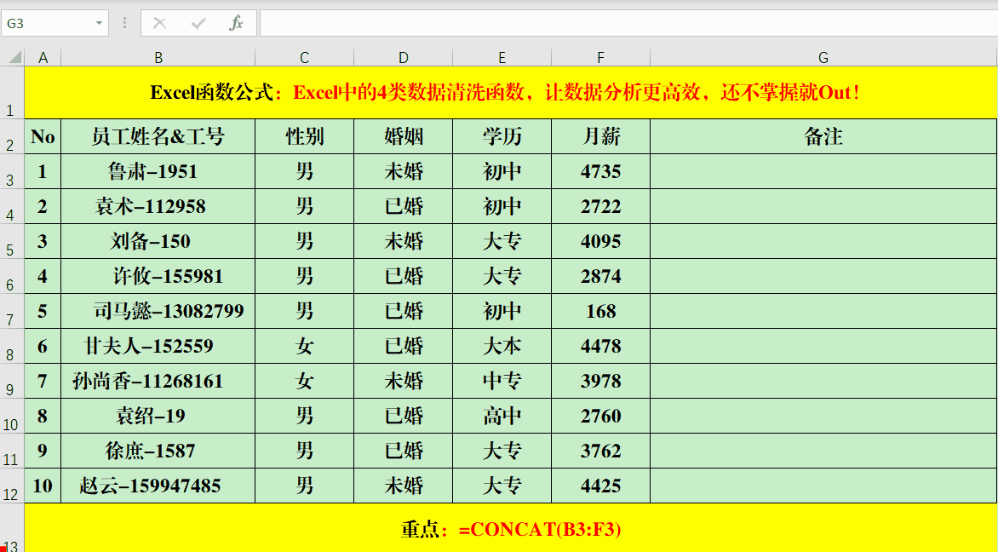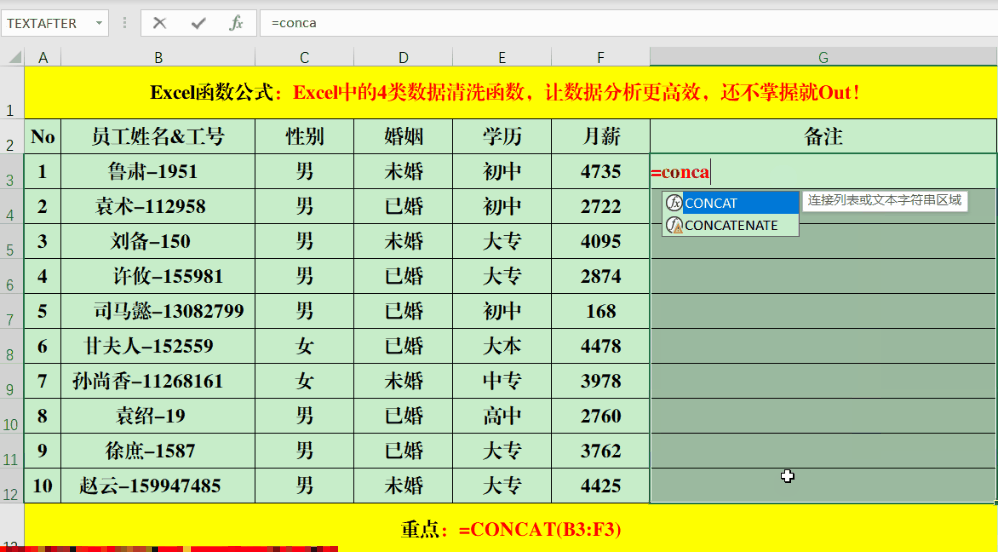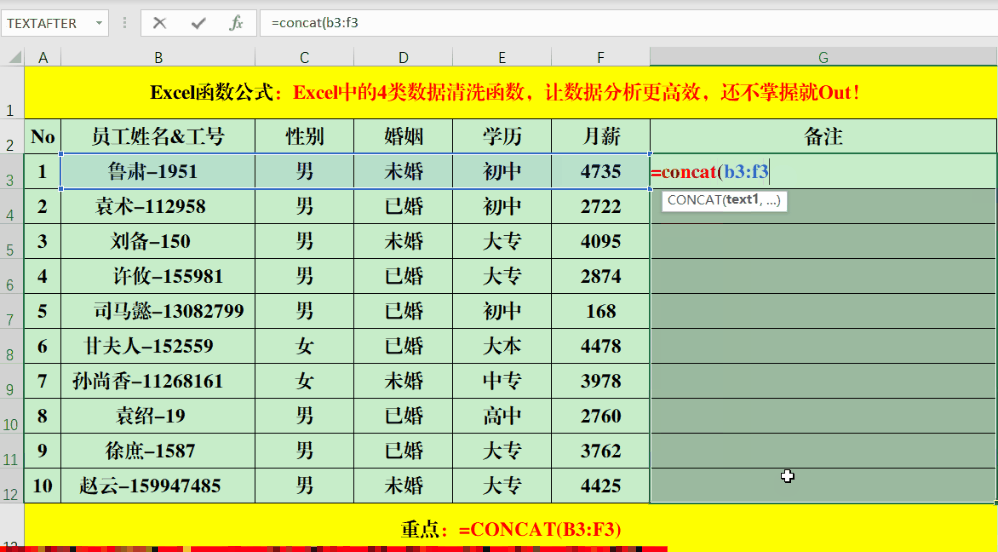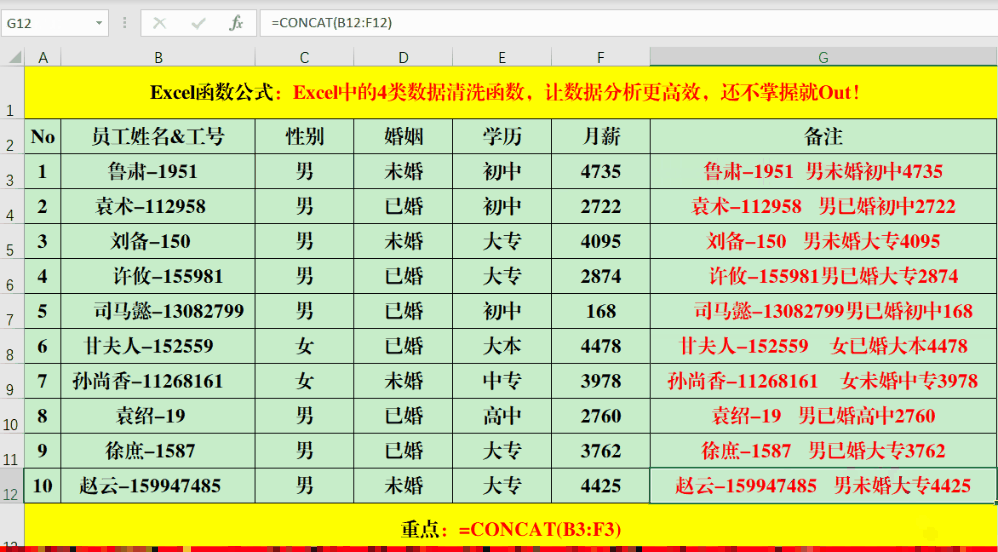
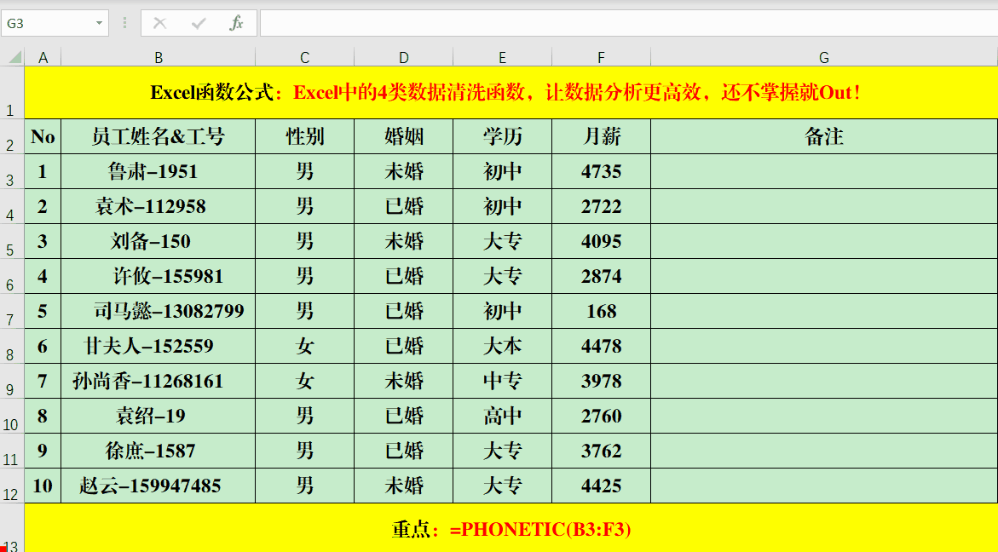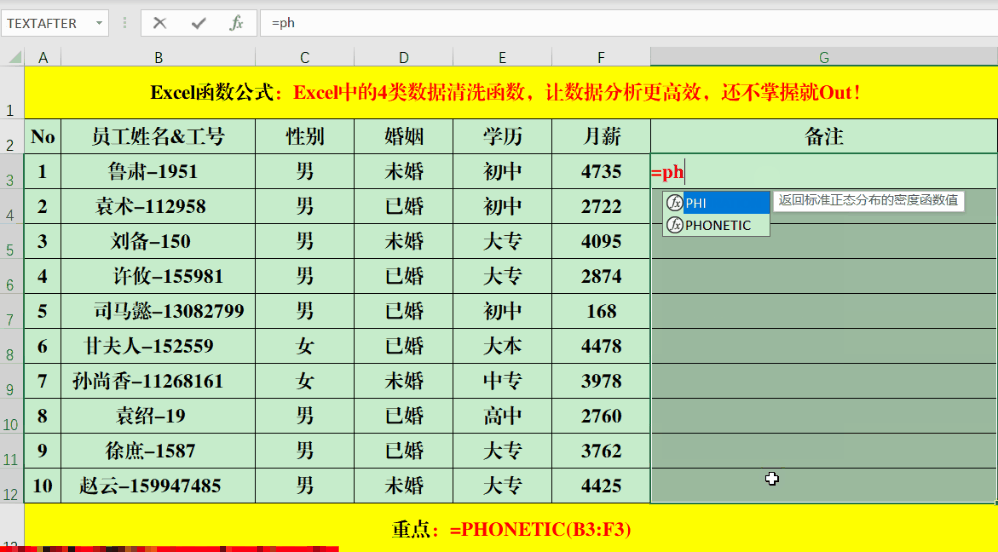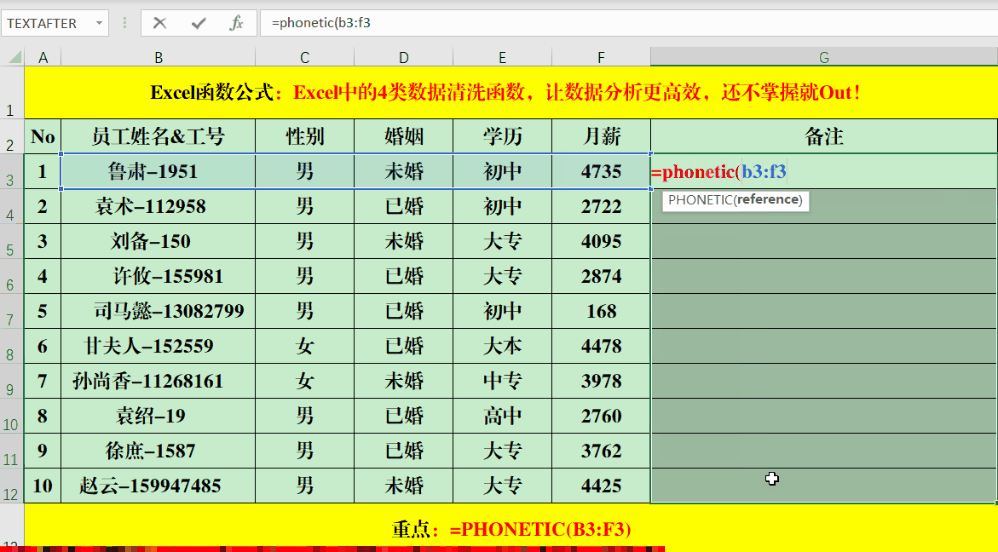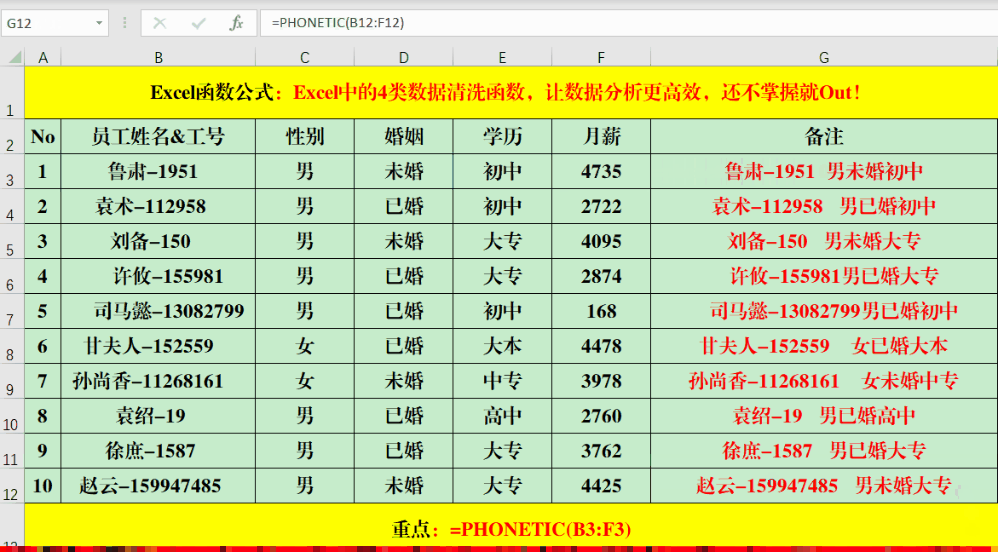
PHONETIC函数可以将非数字的字符串或区域进行合并。比如,你可以在目标单元格输入公式“=PHONETIC(B3:F3)”。但要注意,它无法合并那些没有拼音的字符,像“月薪”这样的字就无法进行合并。操作Textjoin函数的步骤是:首先输入等号,接着输入Textjoin,之后指定分隔符,选择是否保留空格,最后输入需要合并的单元格范围。例如,你可以在目标单元格中输入如下公式:=TEXTJOIN(“、”,1,B3:F3)。此函数不仅能按列合并信息,也能按行进行整合。
在您进行数据处理时,您熟悉了几种字符处理技巧?在数据清洗环节,您是否遭遇过一些挑战?