研究背景
水质指数模型在数据驱动下取得了明显进展,然而,数据中的异常值却大幅降低了其可靠性和精确性。本研究聚焦于爱尔兰的水质指数模型(IEWQI),它同样是一个基于数据的模型。我们主要探讨异常值对模型的影响,这一研究对于实际应用领域具有非常重要的价值。
水质监测和评价的重要性越来越明显,若数据出现异常,评估结果的不准确性可能会给环境管理带来诸多困扰。
研究方法创新
本研究旨在探究数据中的异常值对水质模型的具体影响,首次创新性地提出了一种新方法。此方法巧妙地将机器学习技术与统计学的高效手段相结合。具体操作中,我们运用了两种广泛应用的机器学习算法——孤立森林(IF)和核密度估计(KDE),旨在识别数据中的异常值,并预测在不同条件下水质的变化。同时,我们还运用了五种常见的统计检验方法,以确保结果的准确性。这种多技术结合的方式,为研究提供了更全面准确的分析手段。
以往的研究或许方法较为单一,然而此次研究巧妙地融合了多种技术,从而有效弥补了单一方法可能存在的缺陷。
数据离群值检测
数据集中运用了两种机器学习算法:孤立森林和核密度估计。这两种算法能快速从大量水质数据中找出异常值。孤立森林通过将数据点孤立处理来识别异常点,核密度估计则是依据数据的分布密度来进行判断。
这些技术在应用中表现优异,能快速准确地识别数据中的异常情况,从而为后续分析提供了稳固的基础。
模型性能变化
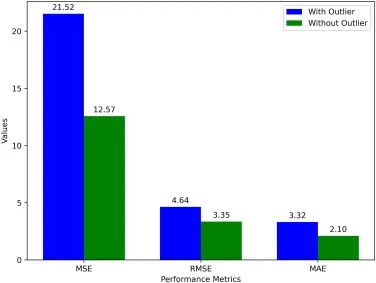
去除输入数据中的异常值后,模型在水质预测方面的能力得到提升,R2指数从0.92升至0.95。这一提升表明异常数据对预测结果影响显著。当数据纯净无杂质、无异常干扰时,模型能更精确地反映水质情况。
在构建水质模型的过程中,我们必须重视数据的质量。对异常数据进行剔除,这样可以提高模型的可信度。
结果验证分析
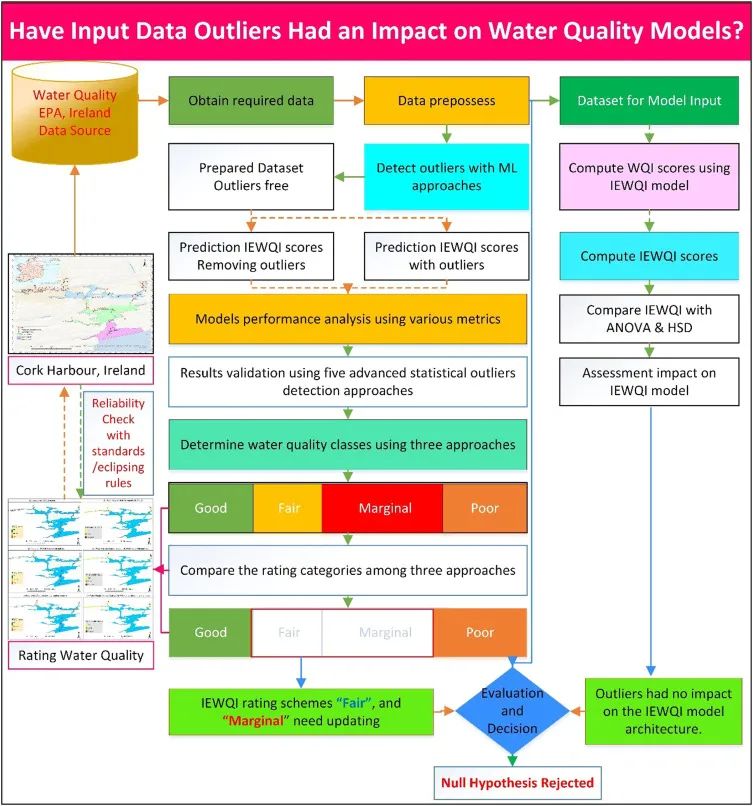
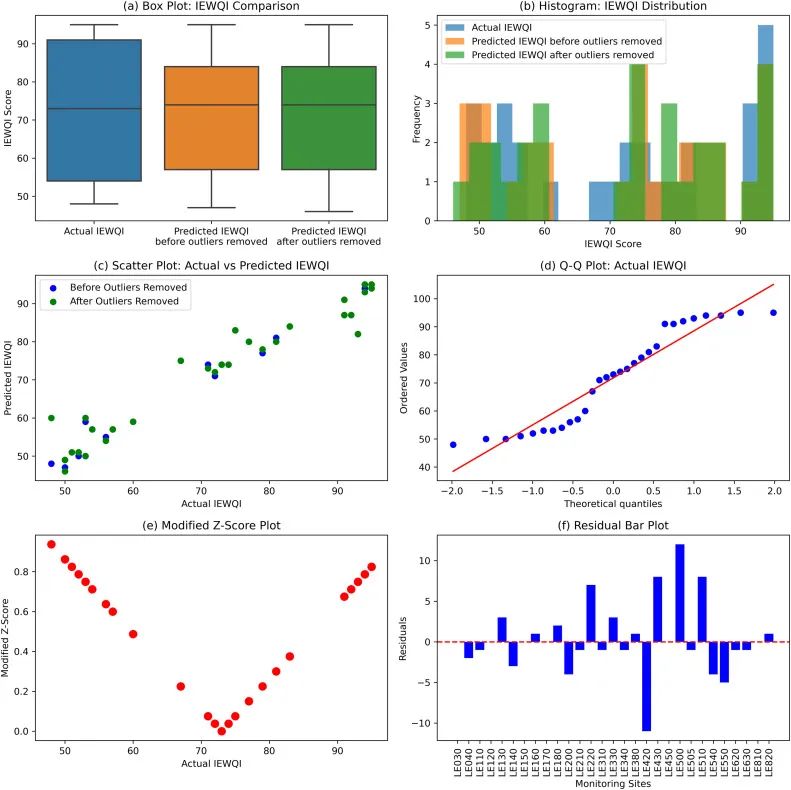
IEWQI分数显示,实际数值与包含异常数据的预测值,以及不包含异常数据的预测值,在统计学上没有显著区别。置信度达到了95%,P值没有超过显著性标准。<0.05。模型不确定性结果表明,使用有异常值和无异常值两个数据集时,模型对最终评估结果的不确定性影响均小于1%。
这些验证结果说明尽管存在数据异常值,IEWQI模型仍具有较强的稳定性和准确性。
研究结果意义
研究结果表明,水质等级和预测的可靠性会受到数据中异常值的影响。即便输入数据存在异常,IEWQI模型仍能对水质进行准确评估。这或许是因为水质指标本身存在时空上的变化特性。这项研究强调了异常数据在水质评估中的关键作用,证实了机器学习在多维度异常数据识别方面的实际效用,同时指出了在环境模型建立过程中,迫切需要采用高效的异常值检测方法。
在环境管理的实际操作中,我们要留意数据中的不正常值,以此来提高对水质评估的精确度。你认为在水质检测的实际步骤里,哪种检测方法对于发现异常数值来说最为高效?