算法的独特优势
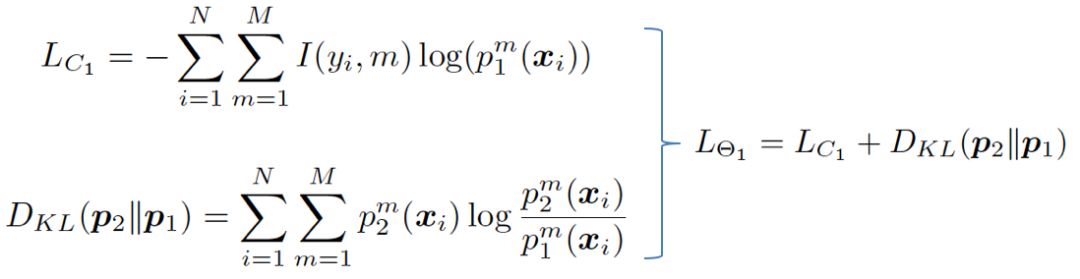
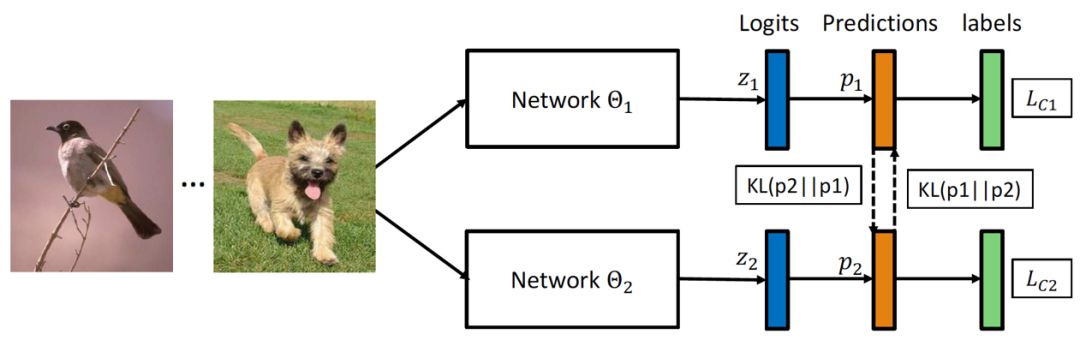
深度互学习算法功能强大,有其独特优势。它利用两种损失函数,使网络能精确辨别不同信息。而且,它能参考其他网络进行概率预测,以此提升自身泛化能力。这好比在学习时获得额外助力,大大提升了网络的学习效率。与模型蒸馏算法不同,此算法不依赖预训练的大网络来辅助小网络,它可以直接助力大网络在训练过程中提高性能。
采用这两种损失函数,网络的分类效果明显提升。在有标签的数据中,网络会进行监督和交互损失的计算;至于无标签的数据,它只计算交互损失。这种设计让网络能更好地从训练数据中提取有用信息。所以,网络在处理数据时更加高效,进而提升了其性能。
实验结果展示
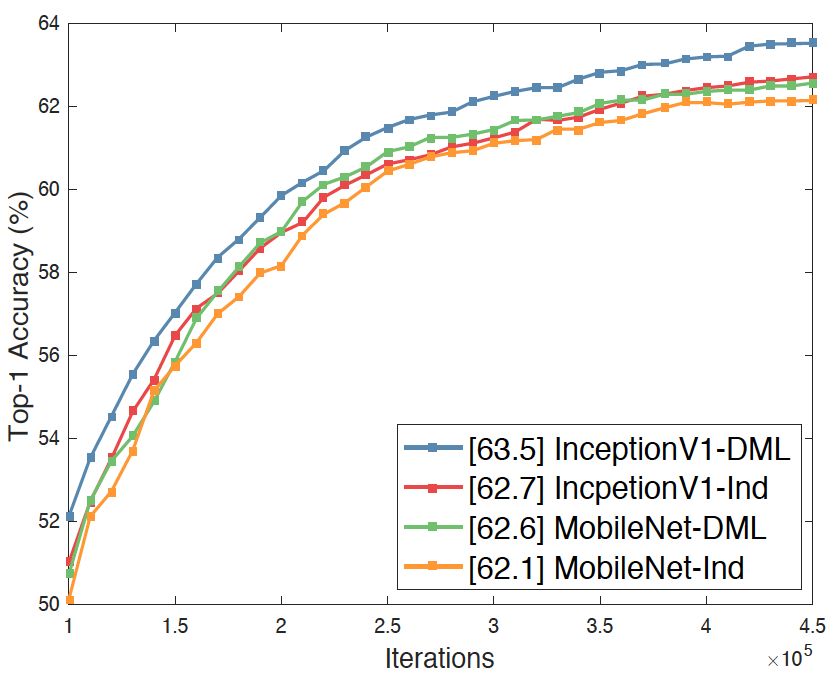
研究在多个数据集上进行了,有力地证明了深度互学习算法的实际效用。在CIFAR-10和CIFAR-100数据集上,效果显著。实验表明,使用互学习训练,网络在处理大规模分类任务时表现更佳。由此看来,这个算法适应性很强,不管数据集规模大小,都能展现出它的长处。

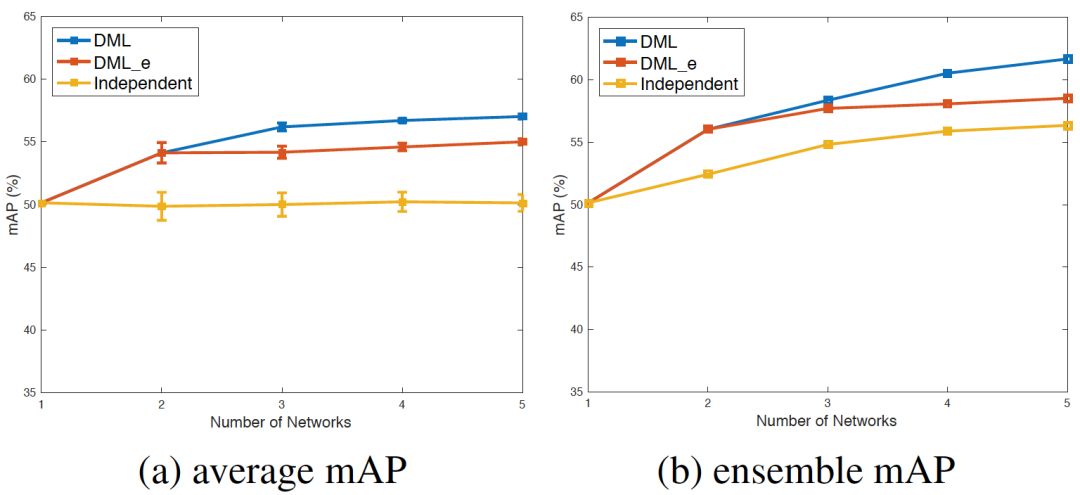
实验表明,网络规模扩大能增强单个网络的表现力。系统若拥有更多教师网络,便能累积更多学习经验,进而更好地掌握特征。这就像学生置身于一个学术氛围浓厚、师资强大的环境中,能学到更多知识和技能。
半监督学习中的表现
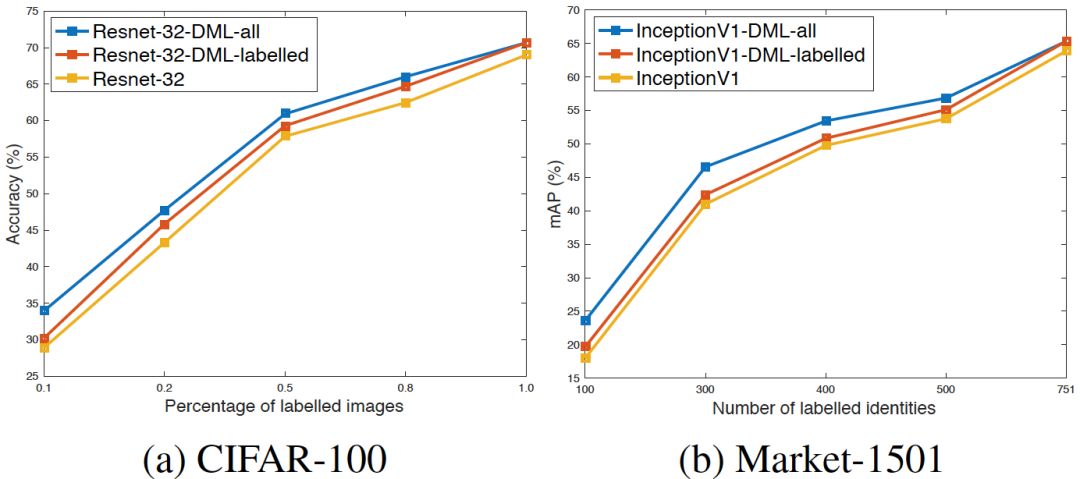
在半监督学习场景中,深度互学习算法表现出色。仅使用标注数据训练,这一策略能显著提高分类准确度。各个网络均随机配置,起初训练时,监督损失较高,交互损失较低,主要依据传统监督损失函数引导,确保算法性能持续增强。
训练持续深化,网络在吸纳知识,对样本类别概率的预估产生差异,交互损失促进了网络间的相互学习。经过这一阶段,网络在半监督学习方面的能力逐渐增强。
泛化性能原理
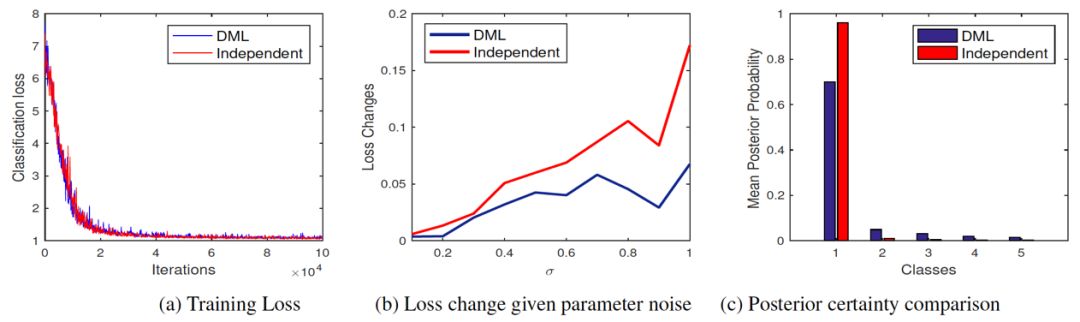
深度互学习算法提升了网络的广泛适用性。训练时,网络会参考其他网络的过往经验来优化学习过程。最终,它能够稳定地达到一个更为平缓的极小值点。这说明,它并非为了追求更深的极小点来降低训练误差,而是选取了一个深度适中且更平稳的极小值点。
这种轻微的、温和的改变,让网络更能抵御噪音干扰,从而增强了它的通用性。就好比在一条平坦的公路上驾驶,更能自如地应对各种突发的情形。
算法作用机制
算法必须保证网络的概率预测与同类网络相匹配,一旦出现不符,将面临严格的处罚。通过这种方式,网络在学习的初期阶段能够维持一致性和精确性。这样的机制促使网络之间相互激励,共同实现进步。
此算法不仅擅长培养出运行速度快的小型网络,而且还能提升大型网络的性能。另外,它也便于在多个网络的学习和半监督学习场景中使用。此算法具有卓越的灵活性和适应性,极大地增加了网络学习的多样性。
算法的潜力与展望
深度互学习算法的潜力十分可观。在众多数据集和学习场景中,它都展现了出色的表现。其独特的设计和运作原理值得深入研究。展望未来,预计它将在更多领域扮演关键角色。
在其他学习任务上,它是否还能展现同样的长处?这个问题确实值得我们去仔细研究。希望各位能对这篇文章给予点赞和分享,若您有独到见解,不妨在评论区留言,让我们一起来交流这个引人入胜的话题!