
机器学习有何卓越之处?它在实际应用中包含哪些关键环节?下面,我将逐一为大家详细讲解。
机器学习概念剖析
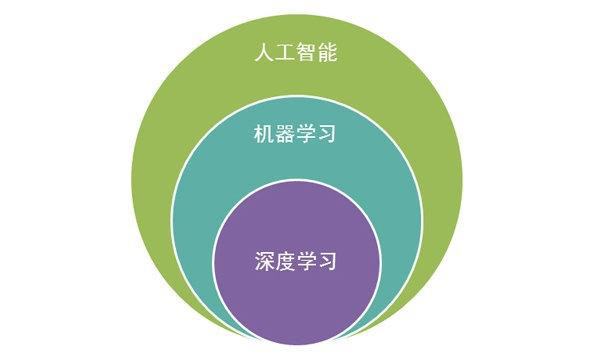
机器学习和人类学习有许多相似点。计算机在得到数据后,会建立模型,然后根据这个模型做出预测。这和人们用经验解决新问题很相似。本质上,通过大量训练数据,模型能掌握深层规律,对新的数据做出精确处理。这一理念是理解机器学习的核心,也为它广泛应用提供了可能。

聚类算法的作用和应用
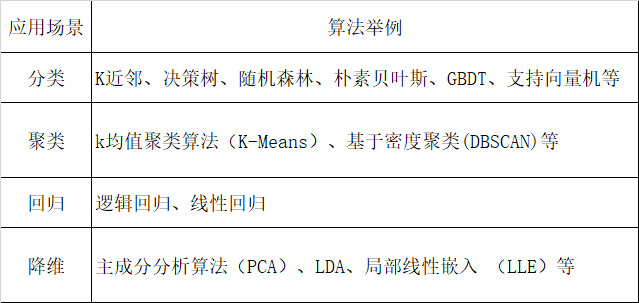
面对未知的数据类型,我们通过分析特征来对相似的数据点进行分类。这种做法属于无监督学习的领域。以RFM模型为例,我们运用客户销售数据来划分群体,对相似数据实施聚类,并据此设立标签。这种方式能够解决相似度难题,有助于我们挖掘数据的深层联系,进而更高效地进行数据分析和决策制定。
数据重要性凸显
机器学习让我们看到了数据中隐藏的巨大价值。产品经理必须熟练运用数据,通过算法来进行预测和做出决策。数据是机器学习的基础,其质量和数量直接影响着学习的效果。比如在精准营销方面,高质量的数据能够让算法精确地向用户推荐合适的商品。
业务场景分析步骤
分析业务场景需要将需求转化为机器学习所需内容。首先,我们要对业务进行概括,找出关键问题;接着,搜集并整理相关数据,留意数据的种类和获取途径;最后,选择合适的算法。这一步骤在机器学习的起始阶段极为关键,每个步骤都直接关系到最终的结果。比如在电商领域,就需要研究消费者的购买习惯。
算法选择的要点
确定了机器学习所需的条件与数据类型后,应选择合适的算法。算法种类众多,主要由算法工程师负责挑选。不同的算法适用于不同场景。例如,对于分类任务,决策树算法是个不错的选择;至于回归问题,线性回归算法更为适宜。正确选择算法,能提高预测的准确性。
数据处理和特征工程
处理数据要留意算法收敛的挑战,尤其是在数据范围宽广的情况下,标准化处理是必要的。同时,存在多种手段来提高数据品质,减少对算法模型的不良作用。特征工程包括从整理好的数据中挑选出有用的信息,为算法模型所用。数据与特征对学习成效有很大作用,要深入理解它们,就必须掌握相关的数据和统计学知识。
读完内容,你是否琢磨过机器学习在某些特定场景下能体现出更出色的表现?不妨在评论区分享你的想法。记得点赞和分享这篇文章!