数据清洗难题
来源:GitHub 本文约3000字,建议阅读5分钟
吴恩达说AI模型里百分之八十的工作要放在数据上,而数据清洗又是保证模型质量的关键步骤,它涉及到领域知识等等,往往很难自动化,MIT最近发布了一个自动数据清洗机器人,有望摆脱手工清洗数据!
数据清洗是数据分析过程中的重要环节,却常常遇到难题。不同数据集的清洗需求和难度各不相同,清洗过程往往需要借助对现实世界的常识判断。比如,在处理城市表格数据时,需要辨别哪些数值不属于该列。目前的方法在表达上存在局限,虽然使用起来方便,但限制条件太多,导致数据清洗过程变得既复杂又不易。
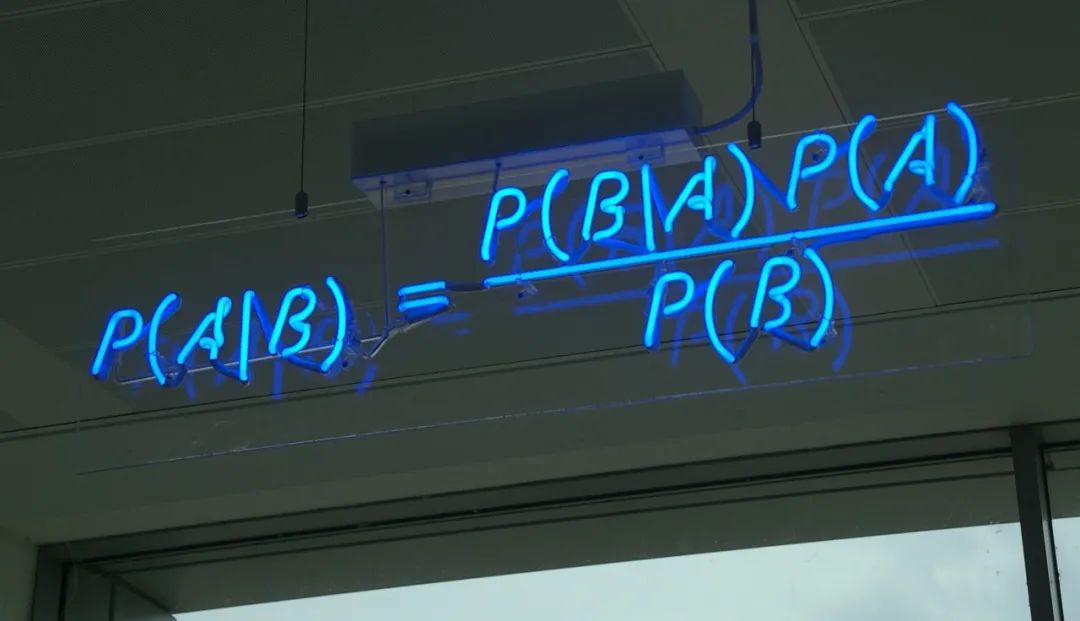

PClean的诞生
麻省理工的研究者们带来了新的曙光,他们成功研发了一种名为PClean的全新系统。这个系统的诞生初衷,正是为了攻克现有数据清洗中遇到的各种难题。科研团队深入理解了数据清洗的难点,并运用了先进技术,打造出了这款有望颠覆数据清洗领域的创新系统。

基于知识的方法
PClean独具匠心,采用了知识驱动的方式来实现数据的自动化清洗。当用户设定数据时,实际上已经融入了数据库的相关背景知识和潜在的问题点。这就像我们向协助清理数据的人详细说明问题一样。举例来说,在处理复杂的数据集时,借助既有的知识库,可以使清洗过程变得更加高效和智能,从而避免了传统方法的盲目性。
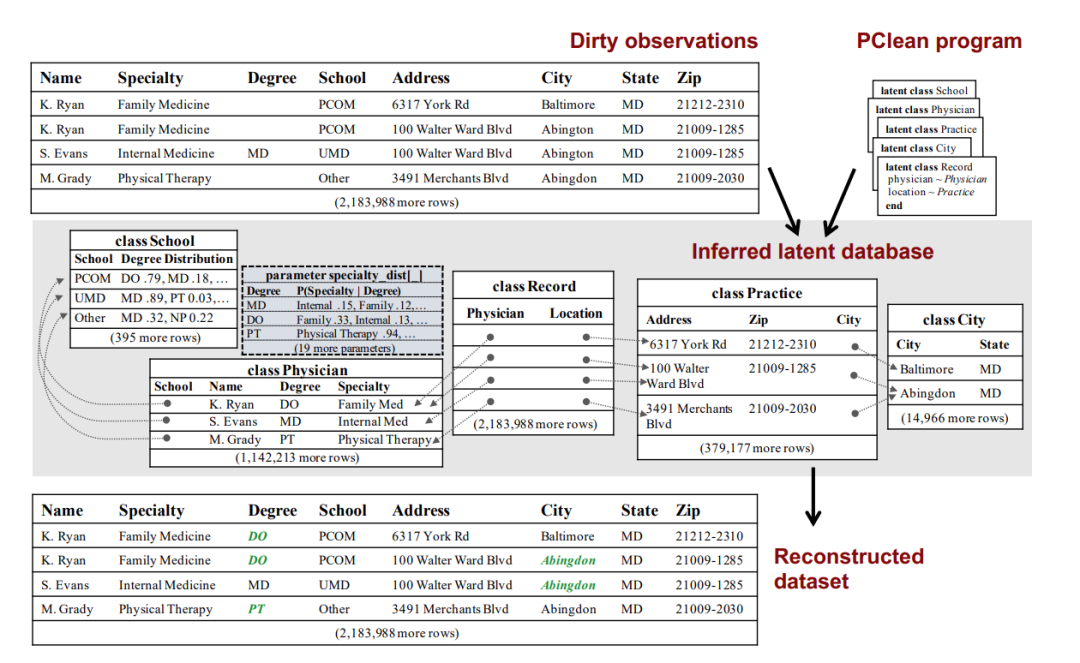
PClean的优势宣传
Agrawal对PClean给予了高度评价,认为它是首个可扩展、设计精良、采用生成式数据建模的通用工具。在他眼中,这个系统指向了正确的道路,成效显著。与现有数据清理技术相比,PClean在多个维度上展现出明显优势。

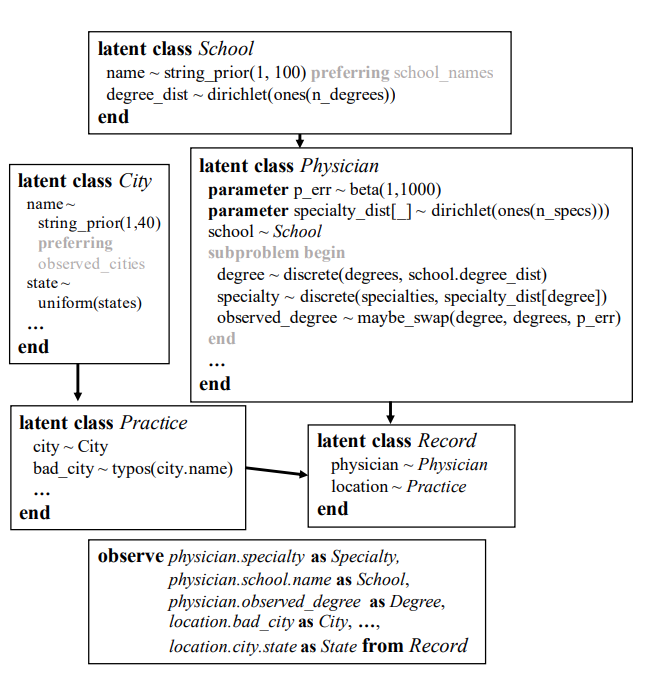
模型创新之处
随着概率编程的进步,麻省理工学院的概率计算项目推出了一个新型人工智能编程模型。这个模型使得PClean能够运用人类知识来解读数据。作为首个贝叶斯数据清洗系统,它拥有三项创新之处。首先,用户可以指导PClean更高效地推断数据库并优化性能。其次,相比其他先进选项,所需的代码量要少得多,大约只需50行代码,就能在准确度和运行时间上超越基准测试。再者,经过作者手动核实,超过96%的受访者对PClean提出的修正方案表示认同。
应用与前景展望
PClean是一款早期的人工智能系统,具备在不确定情况下进行报告、以人类相似的方式进行推理和交流的能力。DeepMind的高级研究科学家David Pfau表示,这款系统能够满足商业需求。因为大部分商业数据都存储在关系数据库和电子表格中,而传统的数据清洗方法并未像深度学习那样取得显著成效。PClean的问世为这一领域带来了新的发展机遇。
你认为PClean能否在数据清洗的未来市场中取得领先地位?期待你的观点,欢迎留言交流,同时请不要忘记点赞和分享这篇文章。