地理数据处理时,遇到不同数据源的高程基准不一致,真是让人烦恼。比如,在将 NASA 的 12.5米分辨率数字高程模型(DEM)与国内DEM结合时,就会产生高度差异。那么,如何用Python脚本实现基准的批量转换?以下将逐一阐述。
数据差异背景
下载自NASA的12.5m DEM数据后,若要将其与国内DEM数据结合,便会发现存在高度上的差异。NASA的DEM数据以WGS84作为高程参考,它测得的是椭球高;相比之下,我国普遍采用1985年的国家高程基准,测量的是大地高。特别是在我国东北地区,椭球高普遍高于大地高。在处理地理数据时,这种差异会对分析和应用产生不利影响。
我的数据涉及xyz个文件,处理这些文件需要编写Python脚本。脚本会将这些文件中基于WGS84坐标系的z值,统一转换成以85国家高程基准为参考的新值。转换完成的数据,才能在国内的地理信息系统内实现更精确的应用。
转换基本原理
该原理依据公式“大地高(Orthometric height)等于椭球高(Ellipsodial height)减去大地水准面差距(Geoid height)”进行阐述。大地高采用的是1985年的国家基准,椭球高则参照WGS84标准,而大地水准面差距的数据可从全球大地水准面模型中获取。
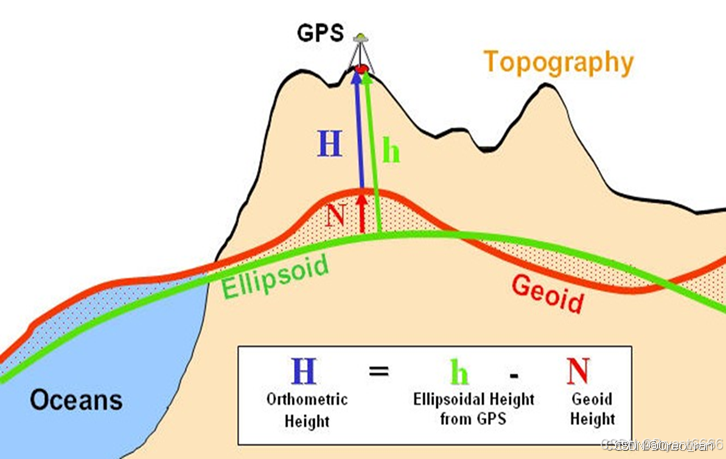
全球有多种大地水准面模型,比如 EGM2008、EGM84、EGM96。我选择了 EGM2008,它的精度是 2.5’。这个选择是基于我的工作需求,EGM2008 提供了 1’、2.5’、5’等不同精度,数值越大,精度越低。2.5’的精度既符合我的分析需要,又不会让数据处理变得复杂。
EGM2008 模型选择
EGM2008模型被选中,不仅因为其精度满足工作要求,而且它应用广泛且受到认可。在地理领域,众多研究和工程建设项目都采用EGM2008进行高程基准的转换。EGM2008对全球大地水准面差异的描述相对精确,为高程基准转换提供了稳定的数据支持。
精度较高的模型虽然分辨率更高,但所需数据量更大,处理难度也随之增加,且可能受到原始数据质量的制约;而精度较低的模型则无法满足要求,可能导致最终转换结果的可靠性下降。相比之下,2.5精度的模型在精度与处理复杂度之间取得了较好的平衡。
模型下载要点
EGM2008模型可在官方网站或特定数据平台获取。下载时务必确保获取的是所需的2.5’精度版本。此外,在下载前,还需核实网站的安全性及数据的精确度。若下载到错误或损坏的模型文件,将可能干扰后续的高程基准转换工作。
下载完模型文件,得好好保存起来。可以按数据种类和精度来分门别类。以后再用到模型,就能迅速找到,这样能提升工作效率。还能防止因为文件管理不善,造成数据丢失或者难以找到。
Python 代码流程
运行代码时,只需更改配置文件的存放位置。特别留意输入的 xyz 文件,确保其投影坐标系为 EPSG:4326。如果不是,需先进行转换。EPSG:4326 是一种常见的地理坐标系,只有基于此坐标系,才能与 EGM2008 模型的数据相匹配。
根据先前提到的公式,代码首先利用EGM2008模型算出各点与大地水准面的高度差,接着用椭球高度减去这个差值,从而得到以1985年国家高程基准为参考的大地高度。之后,将处理后的z值重新写入xyz文件,完成数据转换。输出的文件坐标系统为EPSG:4326。
应用意义及展望
import rasterio
import pandas as pd
import numpy as np
# 1. 配置文件路径
xyz_file_path = "path/to/your_file_xyz4326.xyz" # 输入文件路径(EPSG:4326)
egm2008_tif_path = "path/to/egm2008.tif" # EGM2008 文件路径
output_4326_path = "path/to/output_file_xyz4326.xyz" # 输出文件路径(EPSG:4326)
# 2. 加载 EGM2008 数据
with rasterio.open(egm2008_tif_path) as geoid:
geoid_data = geoid.read(1) # 将 EGM2008 数据载入内存
transform = geoid.transform # 获取栅格的变换参数
# 获取大地水准面偏差 N 值的函数
def get_geoid_undulation(lon, lat):
"""获取大地水准面偏差 N 值"""
col, row = ~transform * (lon, lat) # 经纬度转栅格索引
col, row = int(col), int(row) # 索引取整
if 0 <= col < geoid_data.shape[1] and 0 <= row < geoid_data.shape[0]:
return geoid_data[row, col]
else:
raise ValueError(f"坐标超出范围:lon={lon}, lat={lat}")
# 3. 主处理逻辑
print("正在读取 XYZ 文件...")
xyz_data = pd.read_csv(xyz_file_path, sep='s+', header=None, names=["Lon", "Lat", "Z"])
# 处理高程基准转换
print("正在进行高程基准转换...")
results_4326 = []
for index, row in xyz_data.iterrows():
try:
lon, lat, z = row["Lon"], row["Lat"], row["Z"]
# 获取 N 值
N = get_geoid_undulation(lon, lat)
# 转换为 1985 国家高程基准
H = z - N
# 保存 EPSG:4326 的结果
results_4326.append([lon, lat, H])
except Exception as e:
print(f"处理点 ({lon}, {lat}, {z}) 时发生错误: {e}")
continue
# 保存结果到文件
print("正在保存结果到文件...")
# 保存 EPSG:4326
pd.DataFrame(results_4326, columns=["Lon", "Lat", "Z"]).to_csv(output_4326_path, sep=" ", header=False, index=False)
print(f"处理完成!结果已保存到:nEPSG:4326 文件:{output_4326_path}")
高程基准转换在地理信息、测绘等行业中扮演着至关重要的角色。这项转换产生的精准数据,为城市规划、地质勘探、灾害预警等领域提供了坚实的支撑。未来,我们还可以进一步挖掘这些数据的应用潜力,例如构建更为精确的地形模型,分析地形变化趋势等。
技术进步可能导致更精确、更方便的高程基准转换手段出现。我们需持续留意该领域的新进展,不断对数据处理流程进行优化和升级,提升工作效率及成果品质,以便让地理信息更有效地服务于社会的发展。
在使用地理信息时,你是否遇到过需要调整坐标系统的情况?如果你觉得这篇文章对你有帮助,不妨点个赞,并转发给更多人看看!