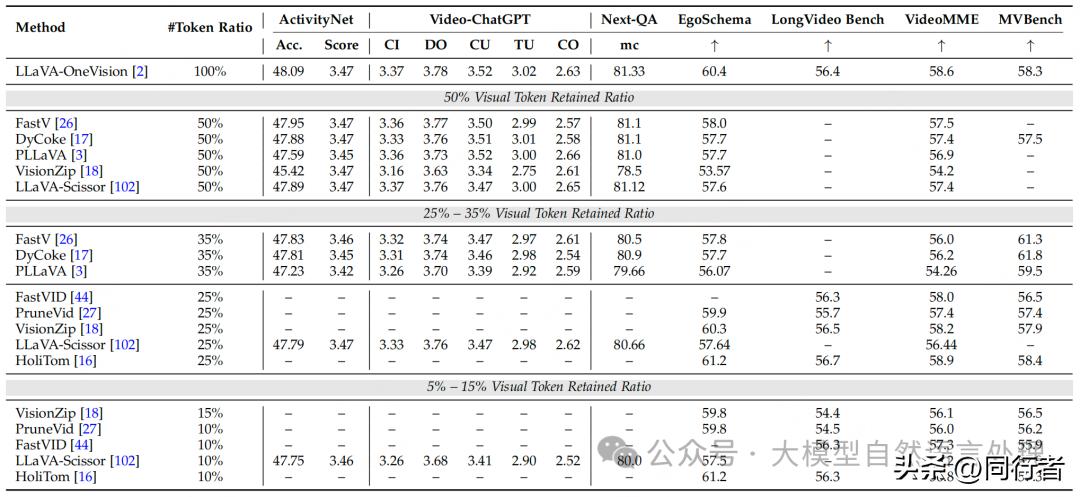
太令人惊叹了,这种能应对各种情境的AI模型确实很强大,不过其内部运作方式又是个难题,文本信息压缩方面也存在不足,这个问题确实值得关注。
多模态大模型潜力与难题
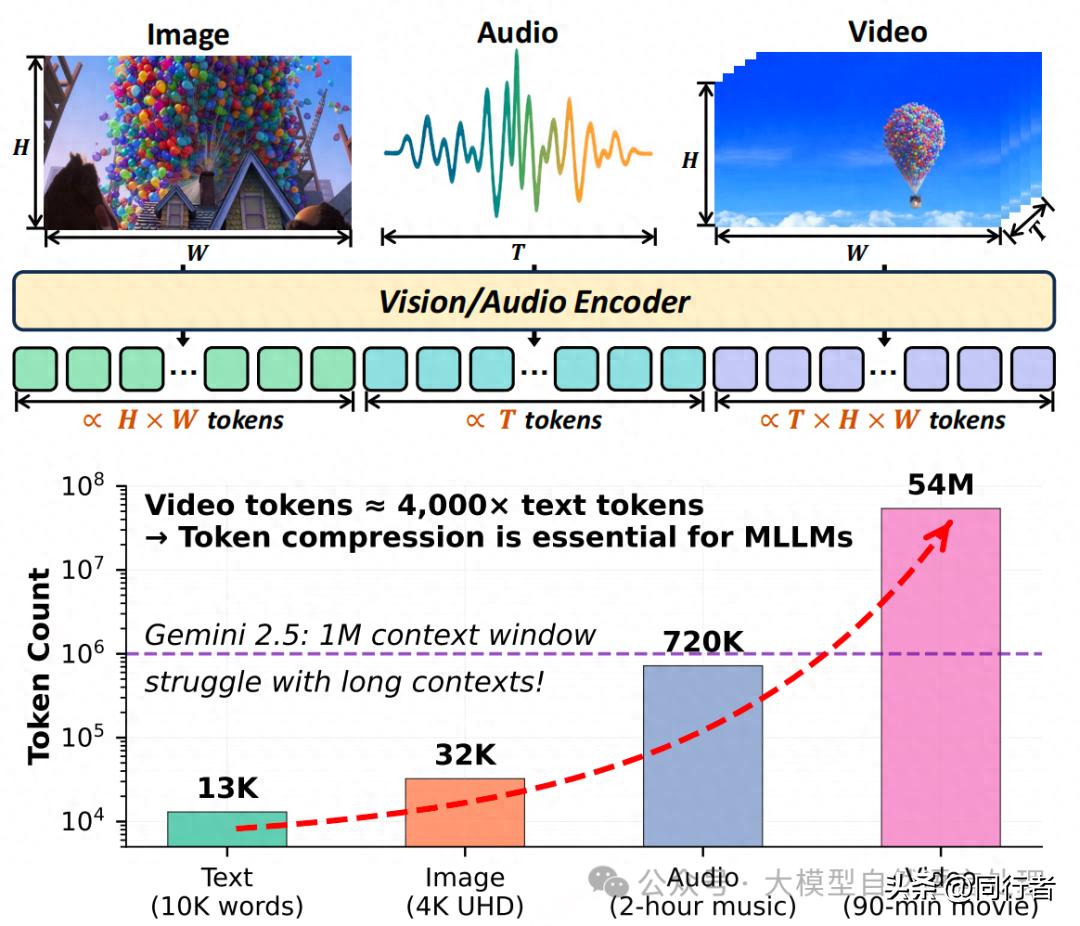
这类人工智能模型功能很强,可以应对高清晰度的照片、时间较长的视频片段以及内容很多的音频信号等复杂场景。由于自关注方法的特性,导致输入数据量增大时,对计算能力和存储空间的要求会急剧上升。以分析一个九十分钟的视频为例,可能会产生五千万个信息单元,这给模型的运行带来了相当大的负担。
文本压缩应用困境
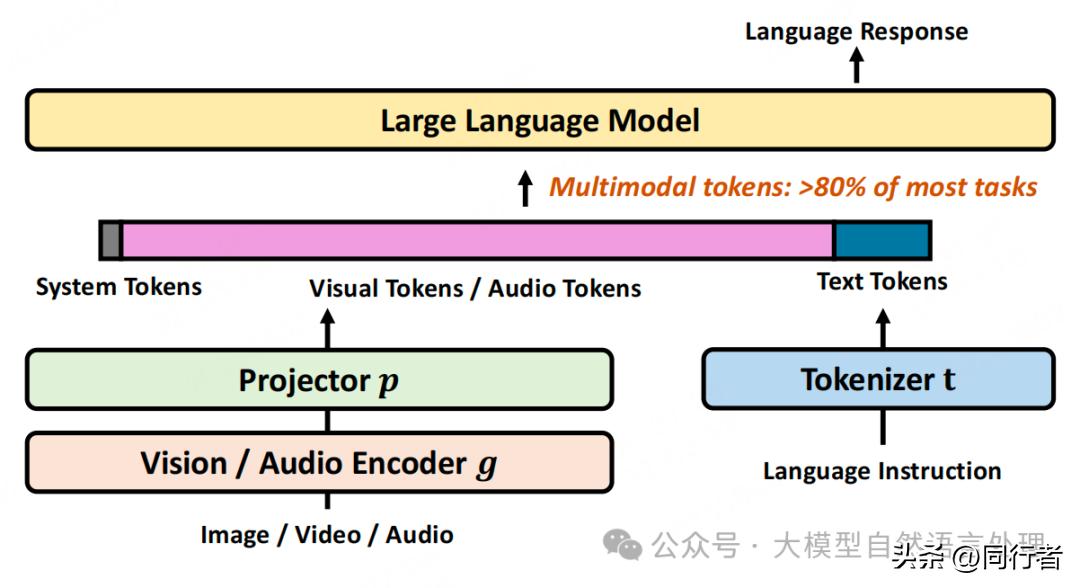
文本压缩方法不适用于多模态模型,由于图像、视频和音频在多模态信息中各自包含特有的冗余特征,例如图像存在空间关联性,而视频则兼具空间和时间上的双重冗余,因此必须制定专门针对多模态数据的压缩方案。
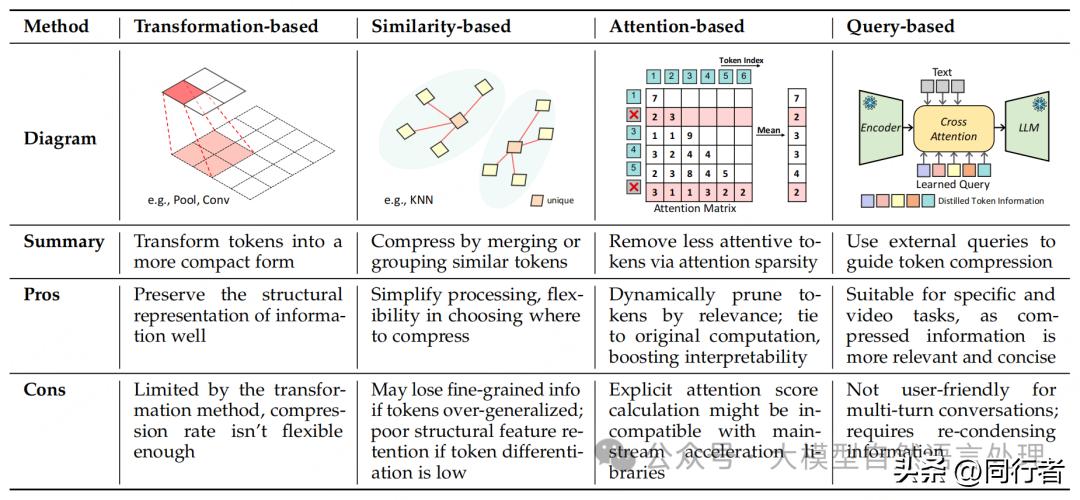
图像中心压缩方法
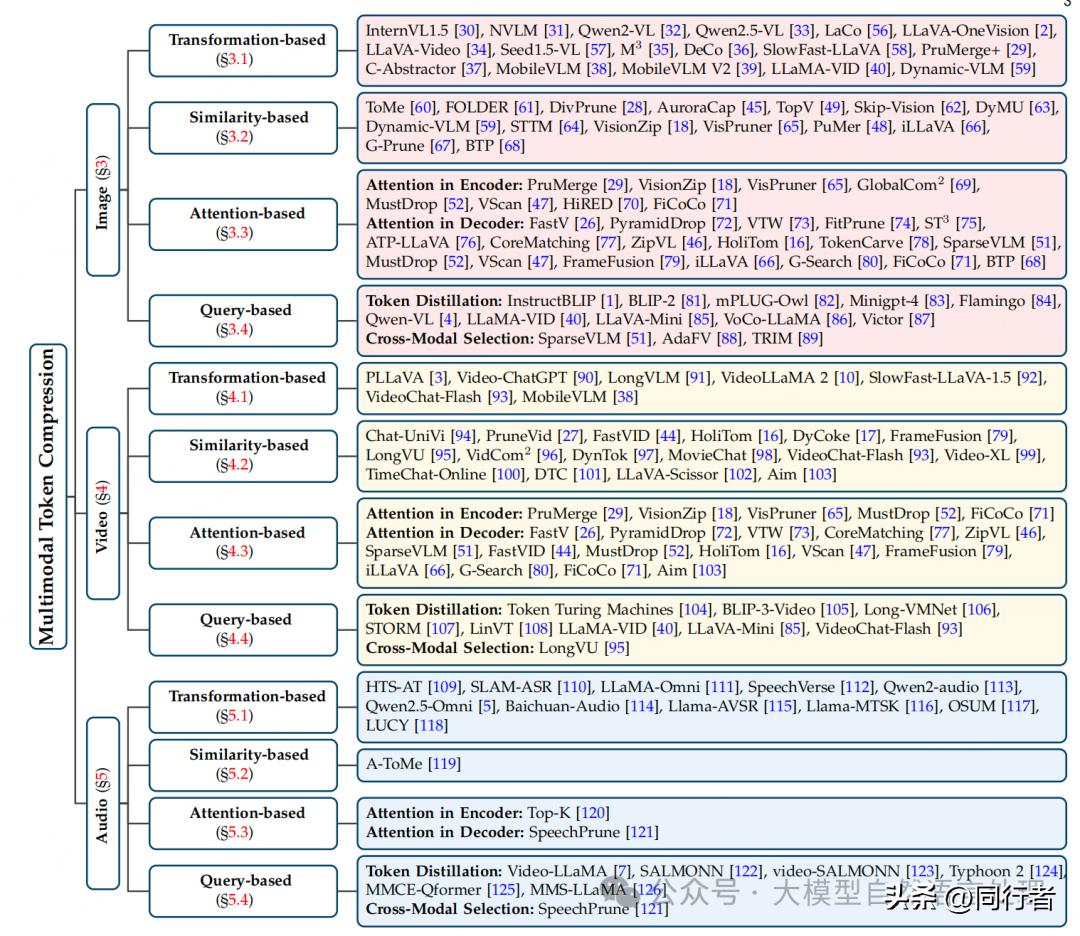
图像中心的token压缩方式有四个方面来处理空间上的多余信息,比如借助空间变换,实施下采样,根据图像空间的特点来减少token的个数,保留核心内容以降低维度,此外还可以运用聚类或者匹配这类方法,找出语义上接近的token并将它们合并在一起,从而缩短序列的长度。
图像查询引导压缩
这些技术借助文本检索来控制视觉标记的精简过程,主要有两种途径,即标记信息传递和跨领域挑选。它们的优点是压缩后的标记和检索词关联紧密,特别适用于以目标为导向的应用,例如图像识别与提问。在许多图像识别与提问的实践中,能够准确保存与所提问题密切相关的细节。
视频中心压缩挑战
视频资料包含位置与时段两种信息,因此其包含的token远比静止画面多,成为机器学习大模型处理时的主要困难。这种资料压缩必须克服空间和时间上的双重重复,既要处理同一画面中邻近部分的一致性,也要处理相邻画面之间的相似性。
视频时间维度优化
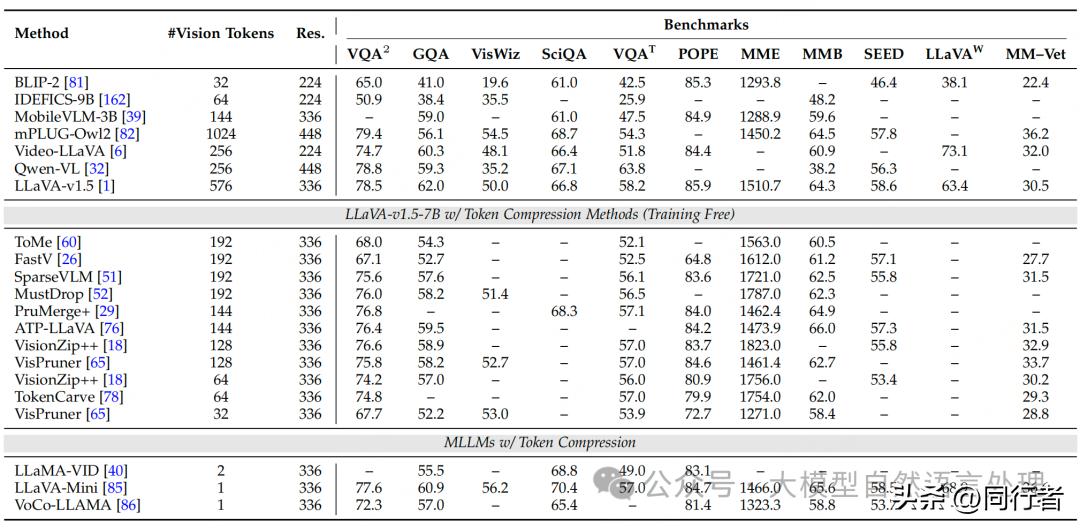
视频中心的token压缩,依据底层机制,存在四种技术路径,分别适用于不同的场景。针对时间维度,可以借助视频时间特征,运用池化或卷积技术来降低token数量,同时也能够通过聚类或相似度匹配,合并重复的帧或token。此外,依据查询与视频帧的相关性动态调整压缩比例,也是一种十分有效的策略,例如LongVU系统,就能根据每帧与查询的相关性得分,灵活调整压缩程度。
音频压缩可以参考图像压缩的转换方式,借助降低采样率的手段来削减音频中的数据单元数量。哪种数据单元的压缩技巧在现实操作中效果更佳呢?敬请点击赞、转发这篇文章,并且发表你的见解。