在学术研究领域,数据堪称瑰宝,而随机数据生成技术则是破解这座宝库的密匙。本文将深入剖析NumPy和Scikit-Learn两款杰出软件,解读它们如何助我们在广袤无垠的数据科学大海中自由航行。
NumPy的随机数据生成魔法
在Python数据科学领域被广泛认可的NumPy模块,包括了高效且强大的随机数生成功能。通过简单的代码编写,便可迅速生成3x2x2的矩阵,极大地提升了工作效率和数据处理能力。
在NumPy中,`np.random.rand`堪称绘画巨匠,仅需定义画布范围,便可绘制出0至1间的随机图案;另一方面,`np.random.randn`则依据自然环境的无序特性,生成具有标准正态分布特征的数组。
“np.random.randint”此强大的函数可生成指定区间内且符合各种矩阵与张量要求的随机整数。其功能丰富多变,不限于简单的随机数生成,更似技艺卓越的魔术师,瞬间响应您所需之数字。
Scikit-Learn的随机数据生成艺术
为精准应对机器学习挑战,引入了针对此特定领域研发的全新Scikit-Learn库。其拥有多样化的随机数据生成工具,可根据各类模型的训练与测试需求,精细调整生成数据。
使用一系列如make_hastie_10_2、make_classification和make_multilabel_classification等工具,我们可以自动生成各类别的模型所需的数据集,无需手动操作,为模型提供专属的训练环境,使之在实际应用中不断提升技能,以应对复杂多变的现实问题。
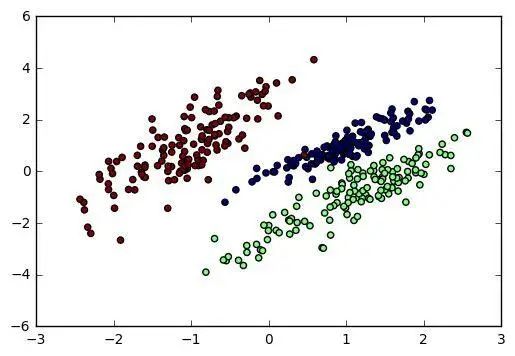
利用高效聚类数据生成工具“make_blobs”,用户可根据需求灵活调整关键参数(如簇数及簇内数据方差等),以模拟各类聚类场景。此过程犹如为聚类算法搭建充满挑战性的迷宫,检验其寻宝能力。
深度分析案例:探讨NumPy和Scikit-Learn在生成随机数据上的巧妙结合
立足实践,理论指引前行。本文通过实例剖析,阐述随机数生成函数在编程领域的应用技巧。
本文将详细探讨使用NumPy创建符合正态分布随机数组之法。通过调整设置参数,我们便可生成具有不同均值与方差的正态分布数据,如同调整乐器音调,每次微调皆能呈现出别样的音乐韵律。
接下来,我们将致力于运用Sklearn平台建立科学适宜的分类模型数据集。通过调整`n_samples`、`n_features`及`n_classes`等关键参数,我们便能创设多样化且逼真的数据情境,从而为分类算法创造充足的发挥空间
随机数据生成的未来展望
在大数据时代背景下,新一代随机数据生成技术与工具迅速崛起。预计未来几年内,我们将见证更为智能化及自动化的数据生成工具诞生,这些工具能依据模型需求自动调整数据生成参数,宛如一支隐形的智慧团队,为我们提供强大支持。
综述来看,NumPy及Sklearn在随机数据生成方面出类拔萃,堪称数据科学界的珍稀瑰宝。借助两大法宝,我们得以轻松生成各类复杂数据,为模型搭建提供理想的训练环境。
本文收尾之际,期待倾听您的心声:您是否期待在数据科学领域研发出某类特定随机数据生成工具呢?敬请在评论区畅谈观点,携手推进产业发展。同时,别忘记点赞与分享文章,以吸引更多热衷于此的同行参与讨论。