Flink作为当前热门的实时计算引擎,在工业界备受关注。其在实时数据体系建设中的应用和解决方案,无疑是值得深入研究和讨论的焦点。
实时计算引擎Flink的应用场景
Flink的应用场景主要分为四大类。首先,是实时数据同步。随着企业数字化水平的不断提升,各部门间的数据需要及时同步并整合。自2018年起,众多企业开始寻求有效的实时数据同步方案,而Flink因此成为了热门之选。其次,是流式ETL。众多互联网企业每日生成海量数据,这些数据在流入时就需要进行及时的清洗和转化,而Flink则能高效地完成这一任务。
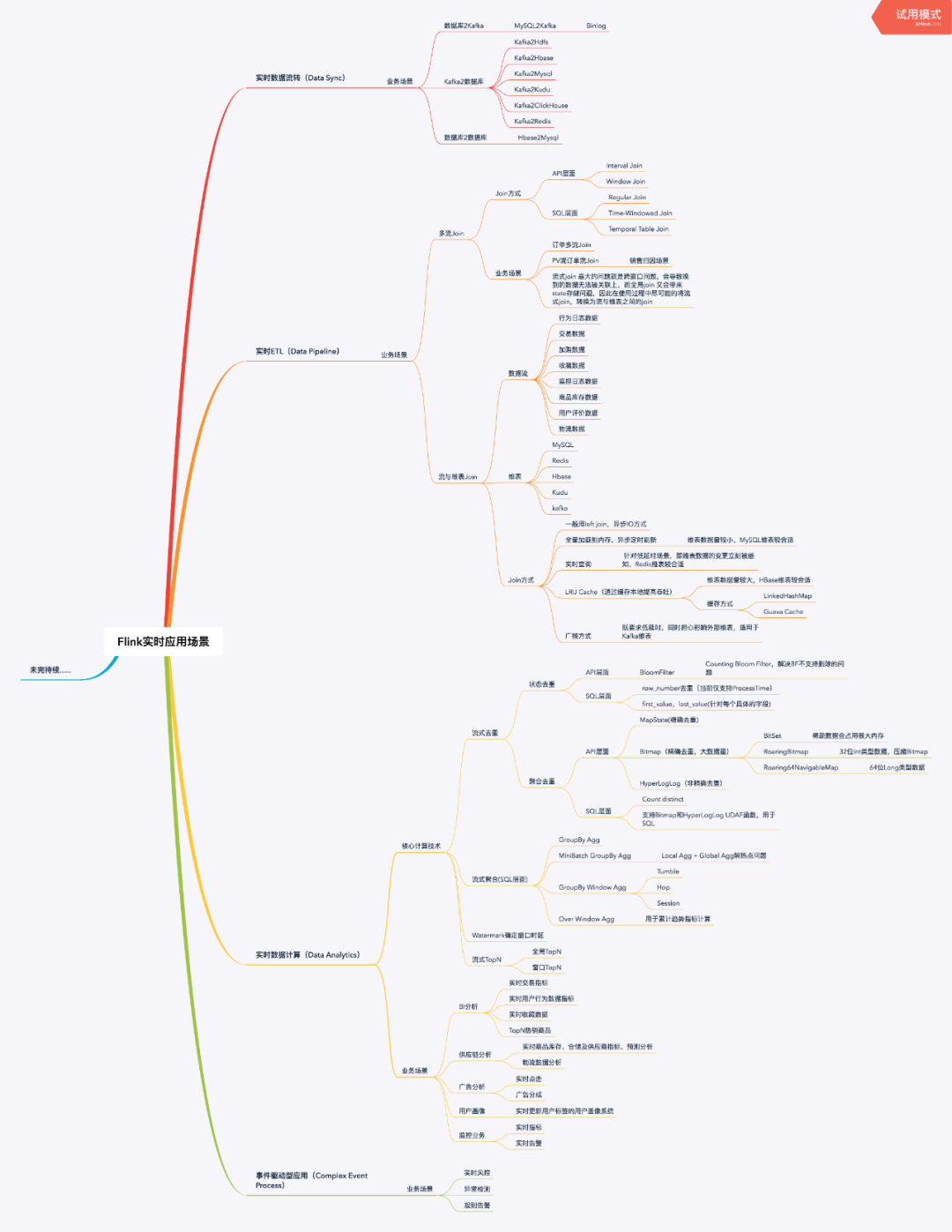
在当今的商业决策中,实时数据分析的需求越来越显著。为了及时掌握市场动向,比如在电商平台的“双十一”期间,企业必须实时跟踪销售数据、用户行为等信息。Flink的实时数据分析能力,让企业能够迅速挖掘数据中的价值。在处理复杂事件方面,某些金融企业面对繁杂的交易事件时,Flink同样展现出出色的应对能力。
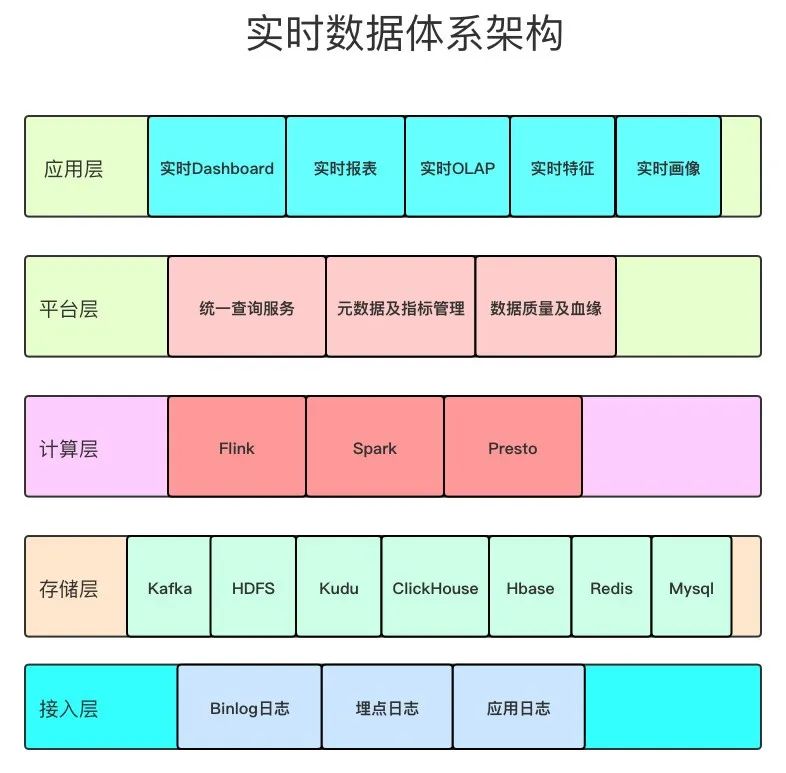
实时数据体系架构
架构共分为五层。首先,接入层是数据的入口,各类数据源,包括企业系统和物联网设备的数据,都汇集于此。接着,存储层在2020年经历了技术革新,面对海量实时数据,我们需关注其高效检索与安全存储。计算层以Flink为核心,负责处理各种业务逻辑,比如数据计算和聚合等。平台层则提供了便捷的用户界面和工具。最后,应用层将处理完毕的数据输出,服务于不同的业务场景,例如数据可视化工具。
实时明细数据层的构建
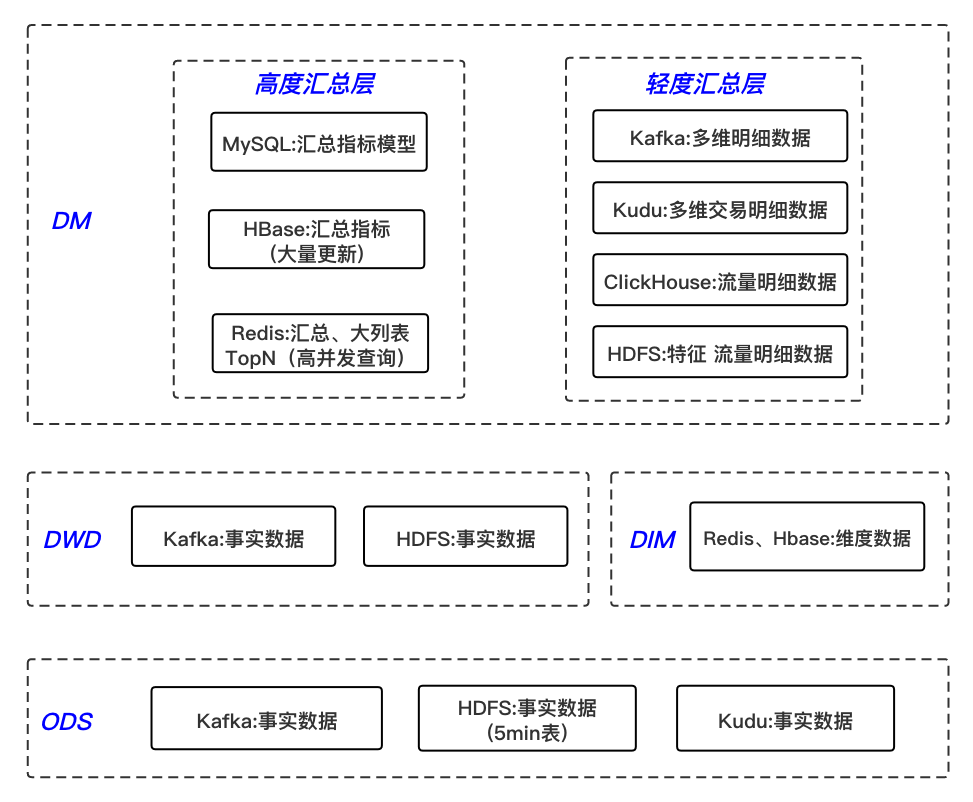
这一层主要进行业务过程建模。以制造企业为例,它们会依据生产流程来构建模型。据调查,许多企业计划在2022年对自身的明细数据进行优化。对关键维度属性字段进行宽表化处理显得尤为重要。比如,在分析用户购买行为时,将用户的基本信息、购买时间等字段进行冗余处理,可以显著提升分析效率。
该层数据来源于ODS层。ODS层包含丰富多样的数据,这些数据经过简单处理后流入本层。值得一提的是,处理binlog日志的流程需要标准化,这对于后续分析至关重要。此外,在流量日志处理方面,实现从非结构化到结构化的转变,以及关联维度字段等操作,都是保障数据可用性的关键。
数据存储的现状及原因
Kafka中存储的数据,确保了数据的实时性和高效流动。以2021年的数据为例,采用Kafka能将数据传输效率提高30%以上。同时,利用Flink将数据写入Hive的5分钟表中,便于查询详细数据,这对于离线数据仓库来说,能更便捷地获取原始数据。这种存储模式全面考虑了实时性、查询便捷性以及为离线分析提供数据等多重需求。
从数据仓库的发展历程来看,Inmon首次提出了这一概念,至今已历经多个阶段。在2010年之前,离线的大数据架构得到了广泛应用。随后,Lambda架构应运而生,为数据处理提供了补充。同时,Kappa架构在一些企业中开始试用。如今,Flink的流批一体架构成为了行业的发展方向,使得数据处理变得更加高效和顺畅。
新存储引擎的尝试
为了满足复杂多维度实时数据分析的需求,Kudu存储引擎被引入应用。以电商企业的订单数据为例,2023年,部分企业开始尝试使用Presto与Kudu相结合的计算方案,探索实时数据分析的可行性。在测试过程中,这种方案展现出能够有效提升查询速度的优势,适应更为复杂的分析场景,或许将促使更多企业考虑进行类似的架构调整。
众多企业正面临是否采纳新型计算存储系统的决策。这一选择涉及成本、效益等多个维度的权衡,必须谨慎对待。与此同时,技术团队还需应对新方案的实施和员工再次培训的双重挑战。
FlinkSQL的用法及优势
public class PageViewDeserializationSchema implements DeserializationSchema<Row> {public static final Logger LOG = LoggerFactory.getLogger(PageViewDeserializationSchema.class);protected SimpleDateFormat dayFormatter;private final RowTypeInfo rowTypeInfo;public PageViewDeserializationSchema(RowTypeInfo rowTypeInfo){dayFormatter = new SimpleDateFormat("yyyyMMdd", Locale.UK);this.rowTypeInfo = rowTypeInfo;}public Row deserialize(byte[] message) throws IOException {Row row = new Row(rowTypeInfo.getArity());MobilePage mobilePage = null;try {mobilePage = MobilePage.parseFrom(message);String mid = mobilePage.getMid();row.setField(0, mid);Long timeLocal = mobilePage.getTimeLocal();String logDate = dayFormatter.format(timeLocal);row.setField(1, logDate);row.setField(2, timeLocal);}catch (Exception e){String mobilePageError = (mobilePage != null) ? mobilePage.toString() : "";LOG.error("error parse bytes payload is {}, pageview error is {}", message.toString(), mobilePageError, e);}return null;}FlinkSQL在统计UV的简单案例中展现了其易用性。众多数据分析师反馈,2022年使用FlinkSQL相较于以往更加便捷。要想顺利使用FlinkSQL,理解Kafka数据解析、TableSchema的初始化以及表的注册是至关重要的。
FlinkSQL的学习成本远低于API方式。对于新入职的数据处理人员来说,掌握它更为迅速,这无疑能提高开发效率。企业在挑选数据处理技术时,是否会倾向于选择FlinkSQL?期待读者在评论区分享您的观点,同时欢迎点赞和转发本文。
public class RealtimeUV {public static void main(String[] args) throws Exception {//step1 从properties配置文件中解析出需要的Kakfa、Hbase配置信息、checkpoint参数信息Map<String, String> config = PropertiesUtil.loadConfFromFile(args[0]);String topic = config.get("source.kafka.topic");String groupId = config.get("source.group.id");String sourceBootStrapServers = config.get("source.bootstrap.servers");String hbaseTable = config.get("hbase.table.name");String hbaseZkQuorum = config.get("hbase.zk.quorum");String hbaseZkParent = config.get("hbase.zk.parent");int checkPointPeriod = Integer.parseInt(config.get("checkpoint.period"));int checkPointTimeout = Integer.parseInt(config.get("checkpoint.timeout"));StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment();//step2 设置Checkpoint相关参数,用于Failover容错sEnv.getConfig().registerTypeWithKryoSerializer(MobilePage.class,ProtobufSerializer.class);sEnv.getCheckpointConfig().setFailOnCheckpointingErrors(false);sEnv.getCheckpointConfig().setMaxConcurrentCheckpoints(1);sEnv.enableCheckpointing(checkPointPeriod, CheckpointingMode.EXACTLY_ONCE);sEnv.getCheckpointConfig().setCheckpointTimeout(checkPointTimeout);sEnv.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);//step3 使用Blink planner、创建TableEnvironment,并且设置状态过期时间,避免Job OOMEnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment tEnv = StreamTableEnvironment.create(sEnv, environmentSettings);tEnv.getConfig().setIdleStateRetentionTime(Time.days(1), Time.days(2));Properties sourceProperties = new Properties();sourceProperties.setProperty("bootstrap.servers", sourceBootStrapServers);sourceProperties.setProperty("auto.commit.interval.ms", "3000");sourceProperties.setProperty("group.id", groupId);//step4 初始化KafkaTableSource的Schema信息,笔者这里使用register TableSource的方式将源表注册到Flink中,而没有用register DataStream方式,也是因为想熟悉一下如何注册KafkaTableSource到Flink中TableSchema schema = TableSchemaUtil.getAppPageViewTableSchema();Optional<String> proctimeAttribute = Optional.empty();List rowtimeAttributeDescriptors = Collections.emptyList();Map<String, String> fieldMapping = new HashMap();List<String> columnNames = new ArrayList();RowTypeInfo rowTypeInfo = new RowTypeInfo(schema.getFieldTypes(), schema.getFieldNames());columnNames.addAll(Arrays.asList(schema.getFieldNames()));columnNames.forEach(name -> fieldMapping.put(name, name));PageViewDeserializationSchema deserializationSchema = new PageViewDeserializationSchema(rowTypeInfo);Map specificOffsets = new HashMap();Kafka011TableSource kafkaTableSource = new Kafka011TableSource(schema,proctimeAttribute,rowtimeAttributeDescriptors,Optional.of(fieldMapping),topic,sourceProperties,deserializationSchema,StartupMode.EARLIEST,specificOffsets);tEnv.registerTableSource("pageview", kafkaTableSource);//step5 初始化Hbase TableSchema、写入参数,并将其注册到Flink中HBaseTableSchema hBaseTableSchema = new HBaseTableSchema();hBaseTableSchema.setRowKey("log_date", String.class);hBaseTableSchema.addColumn("f", "UV", Long.class);HBaseOptions hBaseOptions = HBaseOptions.builder().setTableName(hbaseTable).setZkQuorum(hbaseZkQuorum).setZkNodeParent(hbaseZkParent).build();HBaseWriteOptions hBaseWriteOptions = HBaseWriteOptions.builder().setBufferFlushMaxRows(1000).setBufferFlushIntervalMillis(1000).build();HBaseUpsertTableSink hBaseSink = new HBaseUpsertTableSink(hBaseTableSchema, hBaseOptions, hBaseWriteOptions);tEnv.registerTableSink("uv_index", hBaseSink);//step6 实时计算当天UV指标sql, 这里使用最简单的group by agg,没有使用minibatch或窗口,在大数据量优化时最好使用后两种方式String uvQuery = "insert into uv_index "+ "select log_date,n"+ "ROW(count(distinct mid) as UV)n"+ "from pageviewn"+ "group by log_date";tEnv.sqlUpdate(uvQuery);//step7 执行JobsEnv.execute("UV Job");}}