在机器学习这一领域,异常值检测扮演着关键角色。这就像是在数据海洋中潜藏的未知元素,既具有研究的价值,也带来了不少难题。对于我这类之前主要从事预测分析,如今转向异常值检测的人来说,掌握其中的技巧是至关重要的。
理解异常值监测意义
数据中的异常情况常常揭示出特殊的情形。在现实工作中,例如在一家互联网企业对用户行为进行分析时,不寻常的用户行为或许暗示着潜在的风险或新的商机。在时间维度上,可能是某个特定时间段用户数量骤增或骤减;在空间维度上,可能是某个区域用户表现出与众不同的行为。若无法准确捕捉到这些异常值,便可能遗漏关键信息。此外,异常值的监控还与数据质量紧密相关,若将异常值错误地视为常规数据,可能会对后续的分析和决策产生不利影响。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.svm import OneClassSVM
from sklearn.neural_network import MLPRegressor
from sklearn.ensemble import IsolationForest
from sklearn.metrics import accuracy_score# 生成数据:正常数据和异常数据
np.random.seed(77)
X_normal = 0.3 * np.random.randn(800, 2)
X_abnormal = np.random.uniform(low=-4, high=4, size=(20, 2))
X = np.vstack([X_normal, X_abnormal])
print(X_normal.shape,X_abnormal.shape)
# 标准化数据
scaler = StandardScaler()
scaled = scaler.fit(X_normal)
X_scaled=scaled.transform(X)
X_normal_scaled=scaled.transform(X_normal)
X_abnormal_scaled=scaled.transform(X_abnormal)
print(X_scaled.shape)
true_labels = np.hstack([np.ones(len(X_normal_scaled)), -1 * np.ones(len(X_abnormal_scaled))])
print(true_labels.shape)在金融行业进行风险评估时,从大局出发,不寻常的交易记录可能表明存在欺诈。准确捕捉这些异常数据,有助于提前预防风险,降低损失。
pd.Series(true_labels).value_counts().plot.bar(figsize=(2,2))2分类有监督学习的局限
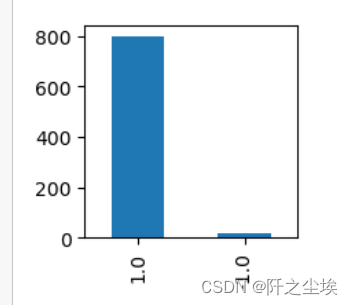
将异常数据与常规数据分成两类看似容易,实则困难重重。例如,某医疗研究项目就遇到了此类问题。观察数据量可知,异常数据在样本中占比极低,导致样本分布不均。这就像在众多健康人中寻找少数病人,两者数量悬殊。此外,简单抽样和数据增强往往无效,因为样本不平衡问题过于严重。再者,在多数实际数据场景中,缺乏预先标记的异常数据,这使得有监督的分类学习变得十分困难。
svmd = OneClassSVM(nu=0.025, kernel="rbf", gamma=0.1)
# Fit the SVM model only on normal data (X_normal)
svmd.fit(X_scaled) # Ensure to use scaled normal data
y_pred = svmd.predict(X_scaled)
print(y_pred.shape)SVMD无监督异常值检测
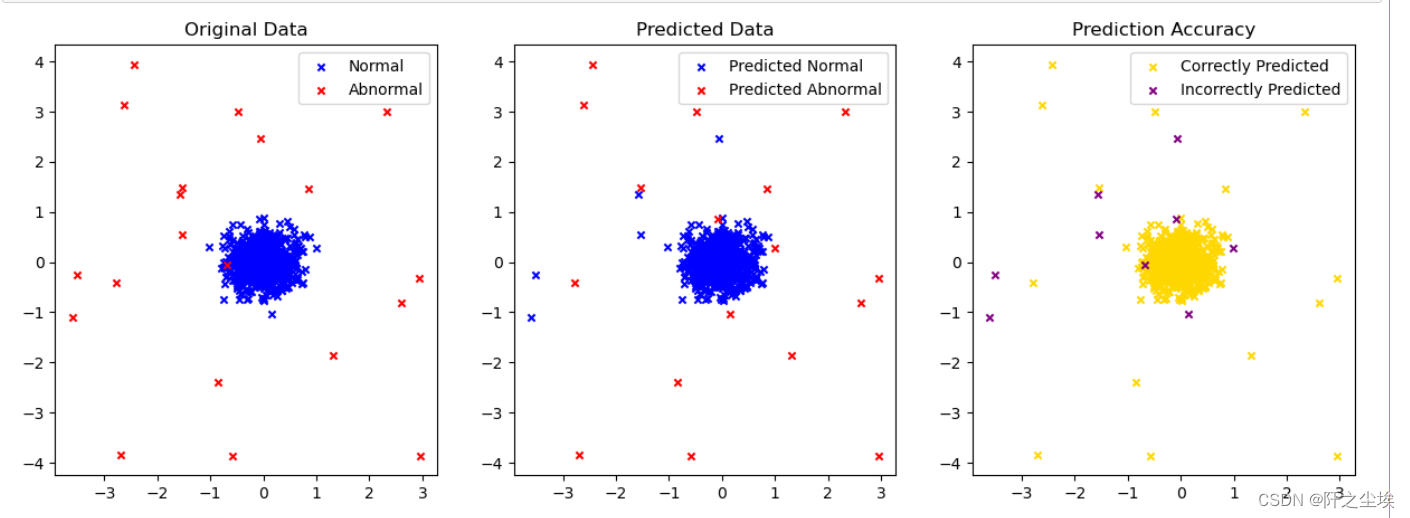
SVMD是一种独特的方法,用于检测数据中的异常值。比如,在电商公司的销售数据中,大部分数据都是正常的销售记录。SVMD的目标是找到一个尽可能小的球体,这个球体能包含大部分正常的样本。它的优点是,基于SVM的概念,非常适合无监督学习。然而,它也存在一些问题,比如预测错误的点没有明显的规律,有时会把一些异常点误判为正常。根据测试数据,虽然这种误判的概率并不高,但确实存在,这可能会对最终的数据分析和决策产生影响。
X_pred_normal = X[y_pred == 1]
X_pred_abnormal = X[y_pred == -1]
# Correctly and incorrectly predicted points
correctly_predicted = y_pred == true_labels
incorrectly_predicted = ~correctly_predicted
# Calculating accuracy using sklearn's accuracy_score function
accuracy_simple = accuracy_score(true_labels,y_pred)
accuracy_simple孤立森林检测特点
# Plotting
plt.figure(figsize=(15, 5))
# Original data plot
plt.subplot(1, 3, 1)
plt.scatter(X_normal[:, 0], X_normal[:, 1], color='blue', label='Normal',s=20,marker='x')
plt.scatter(X_abnormal[:, 0], X_abnormal[:, 1], color='red', label='Abnormal',s=20,marker='x')
plt.title("Original Data")
plt.legend()
# Predicted data plot
plt.subplot(1, 3, 2)
plt.scatter(X_pred_normal[:, 0], X_pred_normal[:, 1], color='b', label='Predicted Normal',s=20,marker='x')
plt.scatter(X_pred_abnormal[:, 0], X_pred_abnormal[:, 1], color='r', label='Predicted Abnormal',s=20,marker='x')
plt.title("Predicted Data")
plt.legend()
# Prediction accuracy plot
plt.subplot(1, 3, 3)
plt.scatter(X[correctly_predicted, 0], X[correctly_predicted, 1], color='gold', label='Correctly Predicted',s=20,marker='x')
plt.scatter(X[incorrectly_predicted, 0], X[incorrectly_predicted, 1], color='purple', label='Incorrectly Predicted',s=20,marker='x')
plt.title("Prediction Accuracy")
plt.legend()
plt.show()孤立森林在识别异常数据方面表现突出,特别适用于处理高维数据。大数据分析企业在分析用户的多维度属性数据时,经常会用到它。它包含一个名为contamination的参数,用来表示异常数据在整体数据中的比例。但在实际的真实数据集中,这个比例往往是未知的,我们只能提供一个大致的估算。这种估算有时准确,有时则不尽如人意,实际应用中可能需要多次尝试调整参数,才能获得较为满意的结果。
自编码器异常值监测
自编码器是自监督学习的一种,其输入数据全部来自自身。在图像处理领域,若神经网络对数据进行压缩和解码重构后,与原始数据差异显著,那么这些数据可能就是异常值。例如,在图像识别研究中,研究人员会为正常数据设定的重构误差设定一个界限,通常选取正常数据重构误差的95%分位数。然而,若正常数据的误差分布不均,那么这个界限可能就不太准确,进而可能导致异常值的误判。
from sklearn.ensemble import IsolationForest
# Create and fit the Isolation Forest model
iso_forest = IsolationForest(contamination=float(len(X_abnormal)) / len(X))
iso_forest.fit(X_scaled) #X_normal_scaled
y_pred_iso = iso_forest.predict(X_scaled)
def plot_result(y_pred,model_name=''):
# Splitting the data into predicted normal and abnormal by Isolation Forest
X_k_normal = X[y_pred == 1]
X_k_abnormal = X[y_pred == -1]
# Correctly and incorrectly predicted points by Isolation Forest
correctly_predicted_k = y_pred == true_labels
incorrectly_predicted_k = ~correctly_predicted_k
accuracy_k_simple = accuracy_score(true_labels, y_pred)
print(accuracy_k_simple)
plt.figure(figsize=(15, 5))
# Original data plot
plt.subplot(1, 3, 1)
plt.scatter(X_normal[:, 0], X_normal[:, 1], color='blue', label='Normal',s=20,marker='x')
plt.scatter(X_abnormal[:, 0], X_abnormal[:, 1], color='red', label='Abnormal',s=20,marker='x')
plt.title("Original Data")
plt.legend()
# Predicted data plot (Isolation Forest)
plt.subplot(1, 3, 2)
plt.scatter(X_k_normal[:, 0], X_k_normal[:, 1], color='b', label='Predicted Normal',s=20,marker='x')
plt.scatter(X_k_abnormal[:, 0], X_k_abnormal[:, 1], color='r', label='Predicted Abnormal',s=20,marker='x')
plt.title(f"Predicted Data ({model_name})")
plt.legend()
# Prediction accuracy plot (Isolation Forest)
plt.subplot(1, 3, 3)
plt.scatter(X[correctly_predicted_k, 0], X[correctly_predicted_k, 1], color='gold', label='Correctly Predicted',s=20,marker='x')
plt.scatter(X[incorrectly_predicted_k, 0], X[incorrectly_predicted_k, 1], color='purple', label='Incorrectly Predicted',s=20,marker='x')
plt.title(f"Prediction Accuracy ({model_name})")
plt.legend()
plt.show()
plot_result(y_pred_iso,model_name='IsolationForest')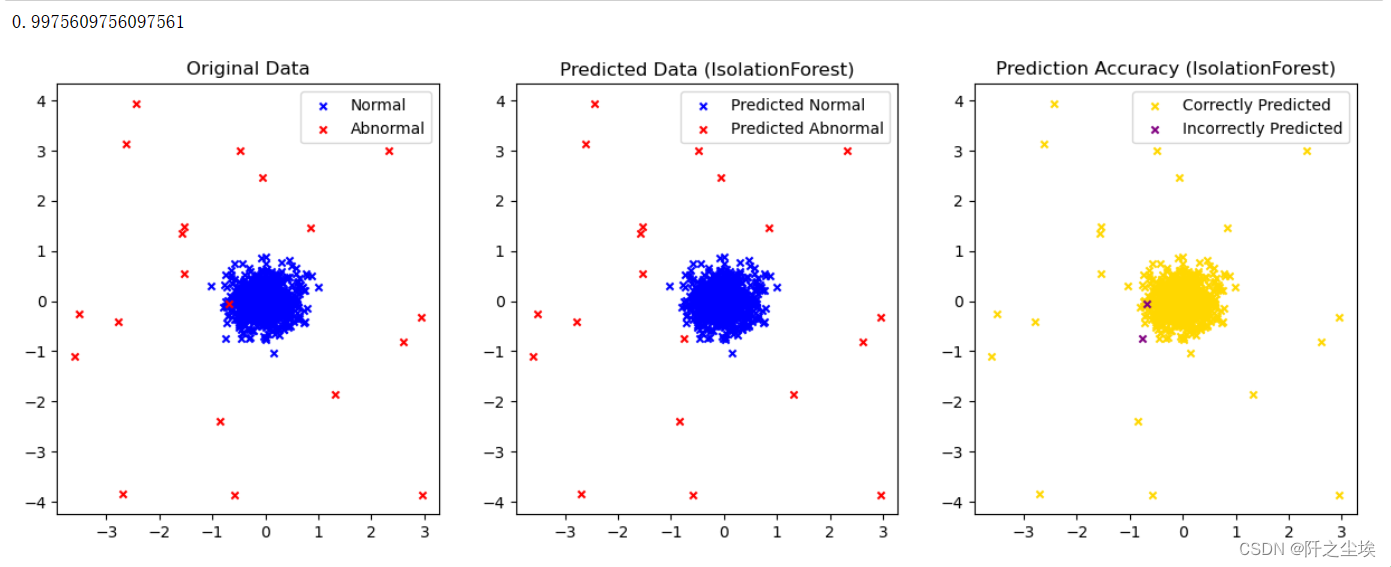
深度学习在异常值监测中的表现
对比实验表明,深度学习在检测异常值方面效果不佳。在一项小型数据分析项目中,由于数据量不大,深度学习算法的表现不如传统的机器学习算法。这或许是因为深度学习通常需要大量数据来帮助模型学习更多模式,而在数据量有限的情况下,其优势难以显现。
异常值监测领域涉及多种技术,比如高斯混合模型等。目前的研究还处于初步对比阶段。要真正了解哪些模型在实际应用中更有效,还需借助大量真实数据进行深入测试。你感觉在异常值监测领域,哪种模型未来可能最具发展前景?