如今,人工智能发展迅速,要打造一个既高效又稳定的系统,关键在于模型的设计、训练、优化和选择。我们接下来将对这一系列复杂的步骤进行详细探讨。
模型设计考虑要素
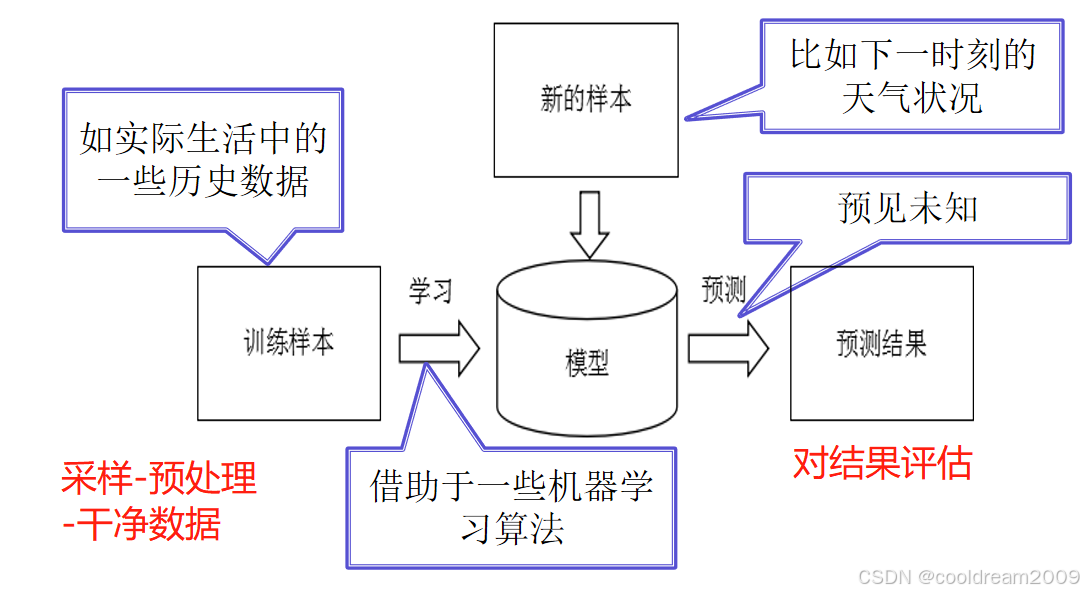
设计模型时,必须综合考虑众多因素。数据本身的特性十分关键,不同类型的数据适合不同的模型。同时,计算资源也不容忽视,尤其是深度学习模型,对资源的需求量相当大。另外,还需关注应用场景的具体需求,比如实时系统对响应速度的要求就很高。在数据量不多时,决策树和支持向量机等简易模型就能满足需求;但当数据量庞大时,深度学习模型能更高效地揭示隐藏的模式。
基于数据量的模型选择
选择模型时,数据量是重要的考虑点。数据不够时,使用简单的模型能迅速达到收敛,还能降低过度拟合的可能性。例如,决策树操作起来很方便,支持向量机在样本不多时也能表现良好。当数据量变大后,复杂的神经网络等模型可以处理更多数据,展现强大的学习能力,精准捕捉数据中的规律。
模型训练目标
模型训练的核心是要保证其能够准确对应数据。为实现这一目标,一般会将数据集分成两个部分:一个是训练数据,另一个是验证数据。训练数据用于调整模型参数,验证数据则用于检验模型的推广能力,防止模型过度适应特定数据。通过不断循环,依据损失函数来优化模型参数,让模型能更高效地掌握数据中的关键信息。
数据集划分作用
数据集被分为训练、验证和测试三个部分,这对于模型的学习极为重要。训练集让模型学会数据的规律,验证集则能及早发现模型是否过于依赖训练数据,从而调整参数。至于测试集,它则是检验模型最终效果的关键,确保模型在实际应用中能表现良好。在不同的模型发展阶段,每个数据集都发挥着独特的角色。
模型优化方法
模型训练阶段,优化策略至关重要。梯度下降法是常用技术之一,它能促使损失函数不断降低,从而找到最优解。同时,正则化处理也必不可少,L1和L2正则化能有效限制参数的复杂性。通过这些优化手段,模型能提升泛化能力,减少过拟合的可能性,并全面提升性能。
优化对模型性能影响
模型性能与优化水平紧密相关。恰当的优化方法可以加快模型的学习速度,减少训练所需时间。经过正则化处理后,模型的稳定性得到加强,对未知数据的处理能力也有所增强。优化后的模型在测试数据集上的表现更出色,预测准确性提升,因此在实际应用中显得更加可靠。
模型测试重要性
模型测试是衡量模型效果的关键环节。这一过程能显现模型在真实场景下的表现,并指出其存在的缺陷。只有经过细致的审查,我们才能判断模型是否适用于实际使用,是否能够满足实际需求。这些测试结果将为后续的模型改进提供依据。
测试发现模型问题
测试过程中,可能会出现模型过度拟合或拟合不足的问题。当模型在训练数据上表现良好,但在测试数据上表现不佳时,我们称之为过拟合;而模型未能充分理解数据特性,则称为欠拟合。通过对测试结果的分析,我们可以有针对性地对模型进行调整,以增强其性能。
模型选择多因素考量
选择模型不能只看它的性能表现,还得关注计算的开销和可解释性等方面。在一些特别需要高精度但不太在乎可解释性的场景下,神经网络这类复杂的模型比较合适。而对于那些对实时性要求很高的任务,计算速度更快的轻量级模型可能更合适。根据不同任务的具体要求,我们需要灵活地挑选最合适的模型。
不同场景模型适配
不同情况下,对模型的需求各不相同。在需要即时响应的场景,比如在线广告推荐,轻量级的决策树能快速给出答案。而对于那些不需要即时反馈的任务,比如疾病预测,使用更复杂的模型可以提高预测的准确性。只有准确把握特定场景的需求,我们才能选择最恰当的模型,确保其发挥出最佳效能。
数据对模型的影响
数据是模型建立的根本。数据不足,会导致复杂模型过度拟合;反之,数据充足,复杂模型便能显现其长处。而且,数据质量也十分重要,数据中的噪声会减少模型的准确性。所以,在设计和选择模型时,必须全面思考数据的相关问题。
数据质量要求
高质量的资料对模型的性能极为关键。资料必须保证精确和全面,不能有错误或遗漏。在收集和处理数据的初期阶段,必须对数据质量进行严格把关。只有这样,模型才能从优质数据中学习到真实规律,提高预测的精确度。
在实际应用场景中,我们面临的一个问题是:如何平衡模型的复杂度和所需的计算资源?不妨给这篇文章点个赞,分享出去,大家可以在评论区展开讨论和交流。