你有没有碰到过那种看上去挺丰富然而实际上却很混乱的数据,从而感觉根本不知道从哪里开始动手?好多分析师在拿到原始数据的那个时候,都会遇上信息分散、格式不一致或者是存在错误的状况,这对后续分析的效率以及准确性造成了直接的影响。
数据合并:联接多源信息
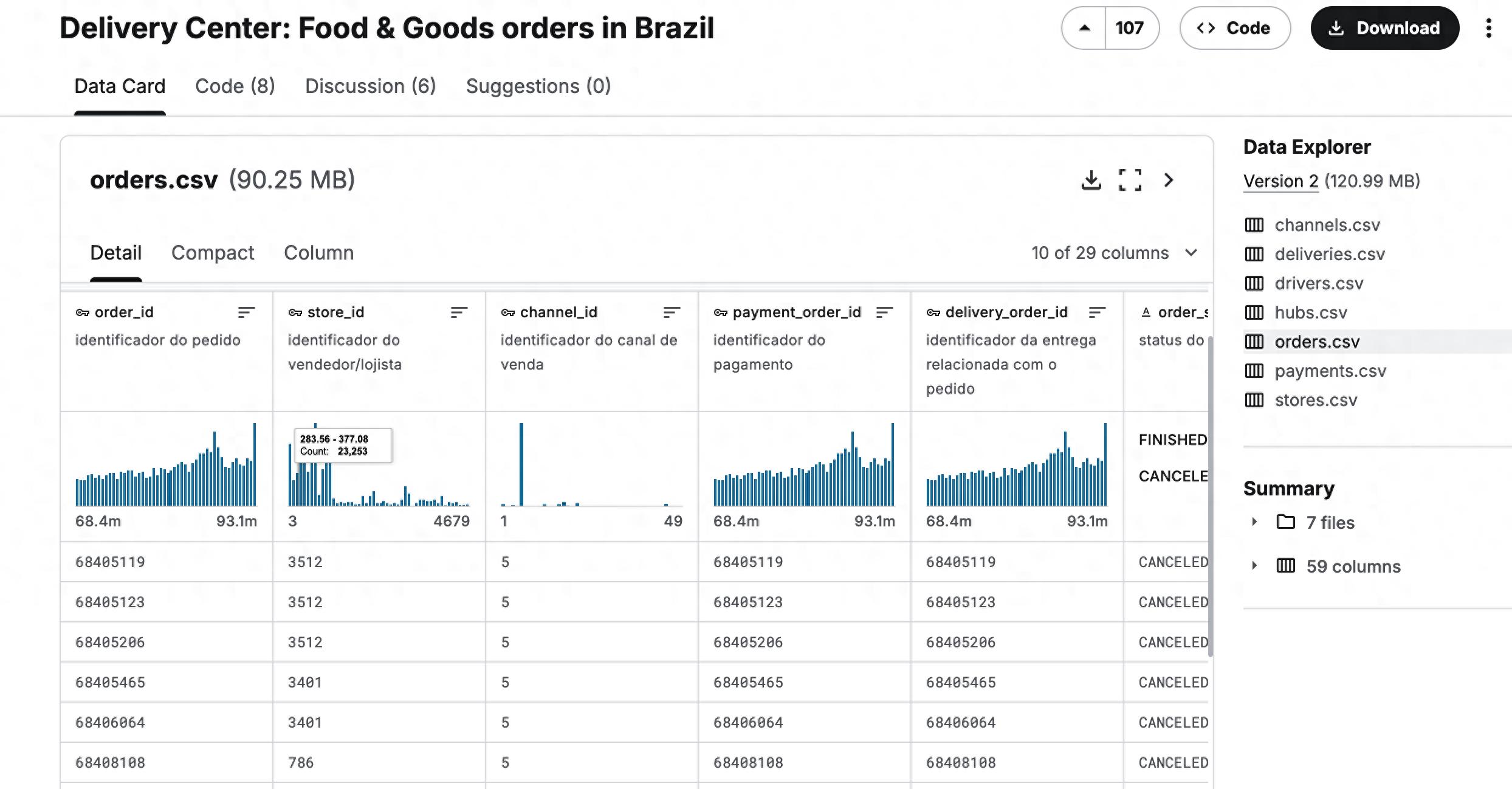
在实际当中,业务方面的数据,常常是存储于多个表格之内的。比如说,有一个表格,它所记录的是巴西食品订单的情况,还有另外一个表格,它记录的则是客户的相关信息。而你则是需要把它们相互联接起来,才能够去开展完整的分析工作的。在Pandas里面的merge函数,是能够如同SQL的JOIN操作那般,依据共同存在的列,像是订单ID,把多个DataFrame组合到一起来的。
df_merged = pd.merge(df1, df2, on='store_id', how='inner')
存在四种主要的联接方式,内联接的情况是只保留双方都具有的记录,左联接为保留左侧全部记录,右联接是保留右侧全部记录,外联接会保留所有记录,缺失部分用NaN填充,这使得你能够依据分析需求,灵活地整合来自不同源头的数据,进而形成一份完整的分析底表 。
合并中的多对多问题
在两边的表之中合并键都并非唯一之际,多对多的合并便会出现,这极有可能致使结果数据行数迅猛地膨胀,数量远远超出你的预期,就好像一个配送中心对应好几种商品,而一种商品又有着多个供应商,直接进行合并的话会产生笛卡尔积 。
import pandas as pd
df_orders = pd.read_csv('delivery_center/orders.csv')
df_stores = pd.read_csv('delivery_center/stores.csv')
# 根据store_id进行合并
df = pd.merge(df_orders, df_stores, on='store_id', how='left')
df.head()
要防止出现这种状况,于合并之前得去查验主键的唯一性,你能够借助DataFrame.duplicated()或者DataFrame.groupby().size()予以核实。要确切知晓表彼此间的实际关系,是“一对一”、“一对多”还是“多对多”,如此方可挑选正确的合并策略,以免出现数据爆炸的情形。
纵向与横向拼接
# 检查主键是否唯一
df_orders['order_id'].duplicated().sum()
df_stores['store_id'].duplicated().sum()
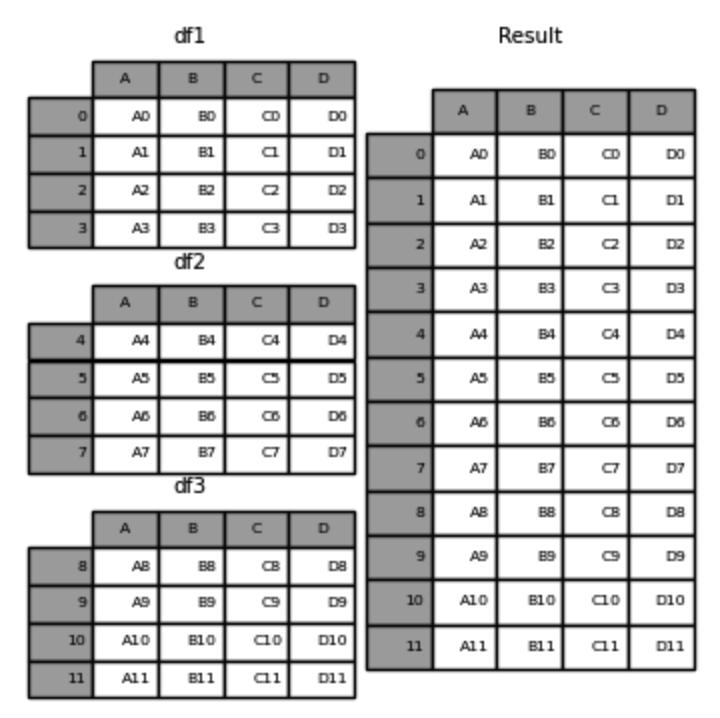
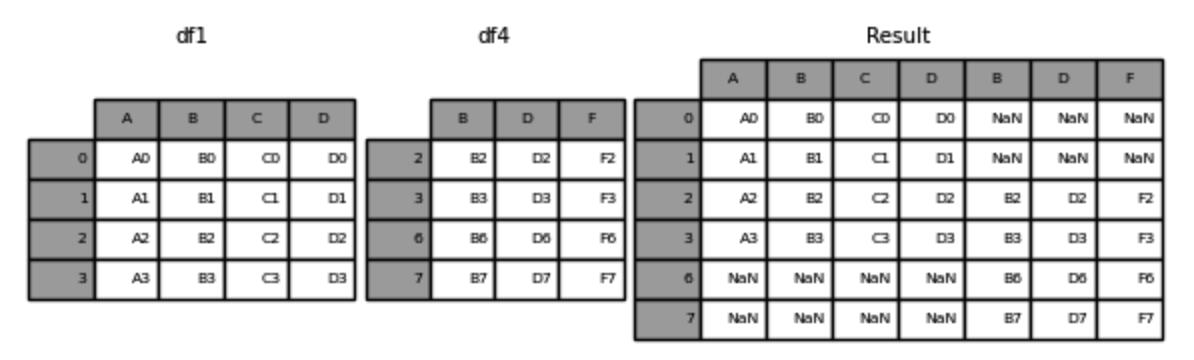
有时候,除了基于键的合并之外,就只需要把那些结构相同的数据表简单地堆叠一块儿,或者把不一样的数据字段朝着横向去进行拼合。在这样的情况下,能够使用concat函数喔。设置axis等于0来实现纵向拼接,常常被用于合并多个月份或者多个地区有关销售的数据。
进行横向拼接时,设置axis=1这一操作的话,就类似于给现有的数据表增添新的数据列。不过要留意,在进行横向拼接期间,行索引的对齐这件事是极其关键重要的。要是索引并非一致的情况,那么就有可能致使数据出现错位的状况,所以必须要保证索引有所匹配,或者使用ignore_index=True这个参数来重置索引。
df_combined = pd.concat([df1, df2], axis=0) # 纵向拼接长表与宽表转换
其数据呈现形式主要划分成长表以及宽表这两种,当中宽表利于人类的阅读过程,每一行归属一个观察对象,每一列属于其某一个属性,长表却更适配机器的处理以及分析,一般涵盖“变量”与“值”这两列,比如,把年份以及各类商品销售额所构成的宽表予以转换,变成“年份-商品类别-销售额”这种样式的长表。
运用Pandas当中melt函数,能够把宽表转变为长表,此时,你得去明确哪一些列属于固定标识,哪一些列要被化作变量。与之相反,借助pivot_table函数,可将长表再转回到宽表,它凭借指定行索引、列名以及数值来重塑数据,并且还支持数据聚合。
处理缺失值与异常值
几乎总是存在真实数据缺失的情况。Pandas 提供了 isna() 来处理,还提供了 fillna() 来处理,也提供了 dropna() 来处理。你可以选择依照情况把缺失严重的行删除。或者选择用均值、中位数、前向填充等方法去补全。关键在于要对数据缺失的原因予以理解,究竟是随机缺失,还是系统缺失,这决定了处理方式。
偏离正常范围的数值被称作异常值,基于四分位距的方式,是一种常见的处理办法,计算出上下四分位数,把高于上界,或者低于下界的数据,划定为异常,剔除,可以选择舍弃,替换为边界值,或者单独进行分析,未经思考地全部删除所有异常值,可能会造成重要信息的丢失,需要结合业务来进行判断 。
df_long = pd.melt(df_wide, id_vars=["user_id"], value_vars=["January", "February", "March"], var_name="month", value_name="amount")字段规范与实战要点
df_wide = pd.pivot_table(df_long, index="user_id", columns="month", values="amount", aggfunc="sum")数据清洗当中还涵盖着字段规范化,像是把文本统一弄为小写,去除掉空格,拆分复合字段,还有正确地转换数据类型,保证日期属于datetime类型,数值是int或者float。一个常见的错误便是在字符串格式的数字之上直接开展数学运算。
倘若要在经历实战时的合并以及紧接着的重塑过后,一定得去核查数据总量、唯一值数量究竟是不是合理的。需要加以规避并且主要存在的“坑”为此包含了多种情况哪:其中有一种状况是在于合并之前根本没有去检查重复键;还有一种状况是在进行重塑之后却忽略了多级索引所具备的含义,从而导致后续索引出现错误;另外呀还有这么一种情形也就是没去先行理处缺失值而是就直接开展建模,最终致使结果产生偏差出现不好状况啦。
在你当下处理多表数据之际,最为经常碰到的棘手难题是什么,是合并键的匹配情况,还是长宽表转换的逻辑,欢迎于评论区当中分享你的经历,要是觉得本文对你存在帮助的话,请进行点赞支持并且分享给更多有需要的朋友呀 。
df_stacked = df_wide.stack() # 将列转换为行
df_unstacked = df_stacked.unstack() # 将行转换为列df_orders.dropna(subset=['order_status', 'order_delivery_cost'], inplace=True) # 删除含缺失值的行