数据质量直接关系分析结论准确度。试想,如有大量数据缺失或存在异常,如何保证分析结果的有效性?因此,本文将探讨利用Python的Pandas库对数据进行全面清理,使其更具可读性和可用性,从而提高分析效率。

pd.read_excel('data.xls') # 读取Excel文件,创建DataFrame。
pd.read_csv('data.csv', encoding = 'utf-8') # 读取csv文本格式的数据,一般用encoding指定编码。
pd.read_table('data.txt',sep='s+',encoding='utf-8',header=0,names='abcdefghij',index_col=['a','b'],usecols=list('abcdefg')) # 读取txt文件
pd.read_json('data.json',orient='values')
data.to_excel("data1.xlsx",sheet_name='Sheet_name_1')
data.to_csv('data1.txt', sep='t', header=True,index=True) # 导出txt
data.to_csv('data1.csv', encoding='gbk',columns=list('abcd'),header=False,index=False) # 导出csv
data.to_json('data2.json',orient='records') # 导出json
缺失值处理:填补空缺,数据不空洞
sportdata = 'data/sportdata.csv' # 体育数据
data = pd.read_csv(sportdata,encoding='gbk') # 读取数据,指定“学号”列为索引列
print(data.duplicated().value_counts())
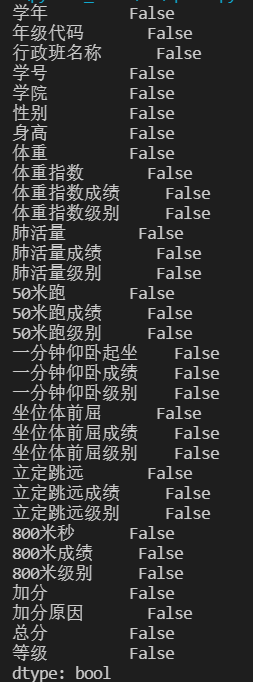
首先,需确定并定位数据中存在的“空洞”问题。借助Python中的Pandas库,借助其中的isnull()函数可便捷地识别缺失位置,这些True和False如同对数据质量的“健康诊断”。此外,isnull().any()命令更能直观地揭示每一列是否存在空值,极大简化了工作流程。
# 删除重复值
data.drop_duplicates(subset=["学号"],keep='first',inplace=True)
print(data.duplicated().value_counts())
接下来,便是针对这些数据空白进行填充处理。可采用mean()、median()或mode()等相关函数,筛选出适宜的均值、中位数及众数予以填充,以使数据呈现得更为丰盈饱和。此外务必铭记在心的是,经过填充后的数据,在后续的分析过程中将会得到更加流畅自如的体验。
异常值处理:剔除“异类”,数据更纯净
print(data.isnull())
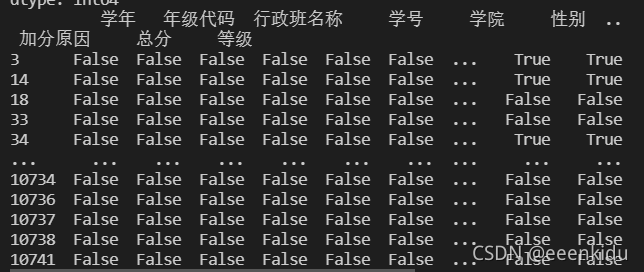
print(data.isnull().any())
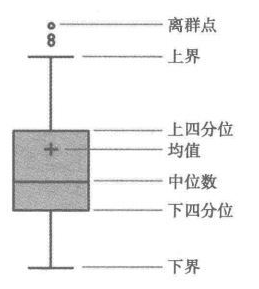
异常值犹如数据中的”异类”,易使分析结果失准。因此,利用describe()函数进行初步检查,识别出超出常规范围的数值至关重要。例如,肺活量高达9999,坐位体前屈达到89,显然属于此类”异类”。

在发现异常值之后,进行适当处理是必然的步骤。可以采取删减或替换等方式来解决问题。借助dropna()函数,可轻易地去除这些”异类”,使数据恢复正常状态。然而,在处理异常值时务必慎重,因为每一个数据都具有其独特的价值。
print(data[data.isnull().values==True])

一致性处理:统一标准,数据更和谐
data.dropna(how='any', axis=0,inplace=True)
print(data.isnull().any())
数据的一致性如同音乐的和声,各个元素需安置得恰到好处。而Pandas中的rename()函式便如精准的“调音器”,调整列名使数据更具条理性;另一方面,astype()函数则是严谨的“校准器”,调整数据类型以保证所有数据均符合规范。
data1 = data[data.isnull().values==True]
print(data1)
print(data1.fillna(0)) # 0填充
除此之外,也可运用sort_values()函数,能够使您的数据得以依照特定的序列进行排序,达到音乐团队般有序的效果。设立concat()函数,恰似您手中挥舞的“指挥棒”,将各类数据集完美结合,形成一幅丰富多彩的“乐章”画面。
数据规整:调整索引和列名,数据更美观
print(data1.fillna("missing",limit=1)) # 第一条缺失值填充
数据的索引与列名犹如服装,清晰整齐方能引人瞩目。在Pandas工具库中,我们既可以使用set_index()函数确保数据无序性得到有效改善,也可借助rename()函数实现对列名的修饰,使其更具美感。

更有unstack()和stack()等功能强大的函数助您轻松实现数据的行转列或列转行的操作,仿佛行走于数据世界的“变形金刚”。值得关注的是,还有fillna()函数这一得力助手,它能为空白信息添补适当内容,使您的数据完整性更为卓越。
print(data1.fillna({"800米级别": "下次再补", "加分": 0}))
数据拼接:连接数据,形成完整图景
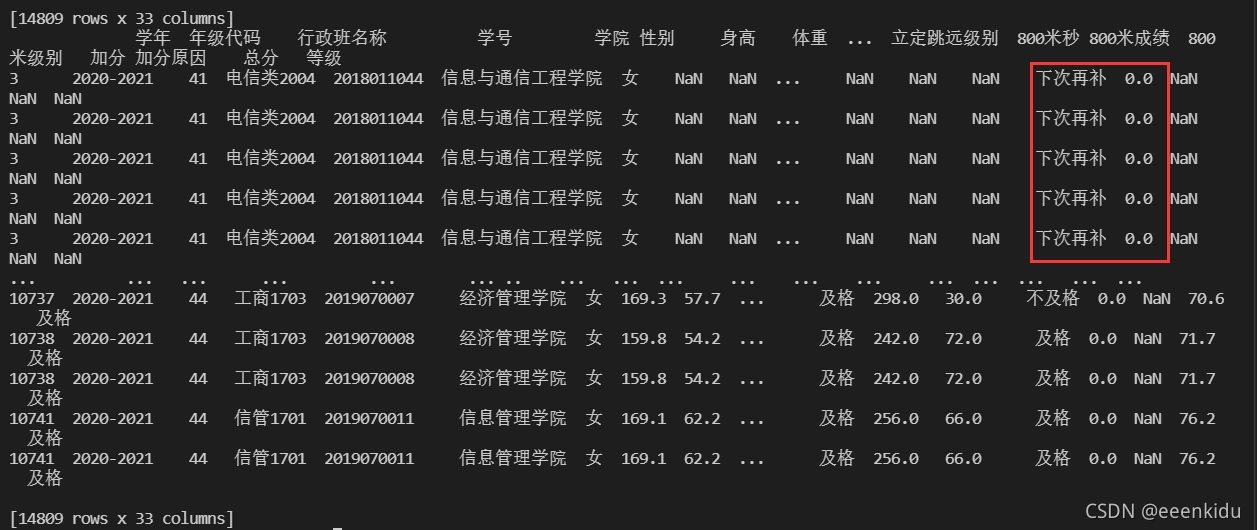
print(data1.fillna(method="ffill"))# 用前一个填充
数据拼接犹如拼图之戏,每部分皆需精准无误。借助于Pandas中的join()函数,各类数据集可有效融合,构建出全面且准确的”图像”。此外,suffixes参数为您提供了识别同键名数据的工具,使得每个部分均能清晰呈现。
print(data1.fillna(method="bfill",inplace=True))# 用后一个填充
此外,merge()函数可实现跨轴合并数据,宛如数据世界中的”魔方”。同时,设定left_index和right_index参数充当数据的”定位器”,以保证每项数据均准确无误地呈现。
print(data1.fillna(data1.median()))# 用中位数填充
数据透视:透视数据,发现隐藏规律
import pandas as pd # 导入数据分析库Pandas
from scipy.interpolate import lagrange # 导入拉格朗日插值函数
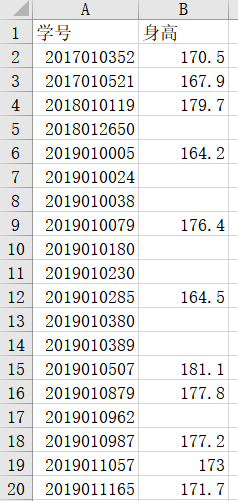
inputfile = 'data/身高.xls' # 身高数据路径
outputfile = 'tmp/身高.xls' # 输出数据路径
data = pd.read_excel(inputfile) # 读入数据
data.loc[(data['身高'] < 130) | (data['身高'] > 200)][['身高']] = None # 过滤异常值,将其变为空值
# 自定义列向量插值函数
# s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
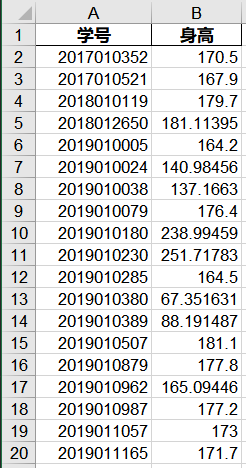
def ployinterp_column(s, n, k=5):
y = s.iloc[list(range(n-k, n)) + list(range(n+1, n+1+k))] # 取数
y = y[y.notnull()] # 剔除空值
return lagrange(y.index, list(y))(n) # 插值并返回插值结果
# 逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: # 如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile, index=False) # 输出结果,写入文件
透过数据透视功能,犹如探险家用望远镜探索未知领域,揭示其隐含规律。借助PythonPanda库提供的pivot_table()函数进行深度剖析,可洞察数据背后的深层奥秘。同时,aggfunc参数如同一把精密的显微镜,助您细致入微地观察数据的每一处细微变化。
其还具备能自由变换数据维度的melt()功能,如同数据领域中的“万花筒”;以及被誉为“分组神器”的groupby()函数,它可依据特定标准对数据进行分组,使各部分细节一目了然。
结尾总结:数据清洗,让分析更精准
import pandas as pd # 导入数据分析库Pandas
# print(data.describe())
outputfile = 'tmp/描述.xls' # 输出数据路径
data.describe().to_excel(outputfile, index=True)
在今日讨论中,我们掌握了使用Python内置Pandas库清理数据的精髓。通过处理缺失值、剔除异常值及调整一致性等步骤,实现对数据的全方位清理。数据的清洁不仅保证了精确的分析结果,还增强了决策的科学性和合理性。

请问您在处理数据清洗时所面临的主要挑战有哪些?又是以何种方式加以攻克的呢?我们诚邀您在评论区分享宝贵的经验与心得。共同探讨,共促成长!请不要忘记为我们的讨论点个赞并分享出去,让更多的人参与到数据清洗的行列中来!
import matplotlib.pyplot as plt # 导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.subplot(1,2,1)
data[["肺活量"]].boxplot(return_type='dict')
plt.subplot(1,2,2)
data[["坐位体前屈"]].boxplot(return_type='dict')
plt.show()