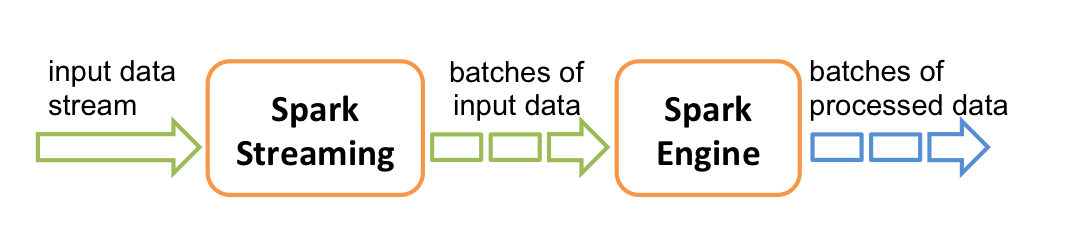
网络信息变幻莫测,SparkStreaming犹如通灵魔手,能够精准捕获并转化数据洪流为珍贵资源。此项技术的独特优势在于,它不仅能实时接收数据流,还能便捷地将其转化为易于理解和运用的形式。

数据流的捕手:SparkStreaming的初始化
在部署SparkStreaming之前,首要步骤是建立StreamingContext这个关键工具。它犹如乐团指挥,指导每个音符的演奏。在StreamingContext建立完成之后,SparkStreaming便能即时感知并处理数据,展现出卓越的性能。
首先要明确的是SparkStreaming的数据来源,分别为对话式聊天厅数据Kafka,持续流逝的数据平台Kinesis以及源源不断的实时数据TCPockets等。这些不同类型的数据源犹如自然界中的珍品,等待着我们去发掘与欣赏。
DStream:连续数据流的抽象
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark_version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark_version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark_version}</version>
</dependency>
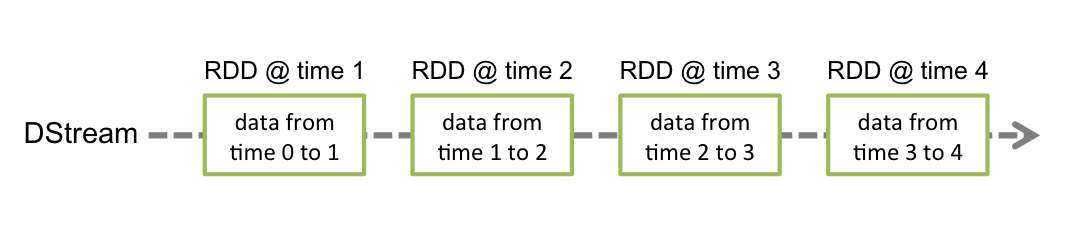
在Spark流处理技术中,DStream享有举足轻重之地位,其特征即为持续不间断的数据流。如同永不止息的水流,每时每刻都有大量数据碎片涌现。我们可以依据输入的数据流生成DStream,或者运用高级操作对其他DStream进行处理,从而丰富新的DStream的构成要素。
package cn.wsj.mysparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object NcWordCount {
def main(args: Array[String]): Unit = {
//创建SparkConf对象
val conf: SparkConf = new SparkConf()
.setAppName(this.getClass.getName)
.setMaster("local[4]")
//创建StreamingContext对象与集群进行交互,Seconds(5)表示批处理间隔
val ssc: StreamingContext = new StreamingContext(conf, Seconds(5))
//创建一个将连接到主机名xxx端口xxxx的DStream,例如localhost:9999
val line: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.237.160", 1234)
//计算每批数据中的每个单词并打印
line.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_).print()
//启动Spark Streaming
ssc.start()
//等待计算终止
ssc.awaitTermination()
}
}
在DStream架构中,多个连续的RDD元素作为核心要素存在。RDD充分体现了Spark对静态分布式数据集的精妙描绘,如同小溪中的卵石,各自独立却共同推动水流前行。通过对这些RDD进行精细操控,我们得以实现数据的高效转化与精细处理。
数据魔术处理技术:映射,压缩,结合与窗口
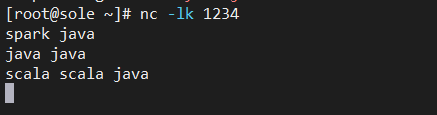
# 安装网络工具netcat
ymu -y install nc
# 打开一个socket ,这里我开启的是1234端口
nc -lk 1234
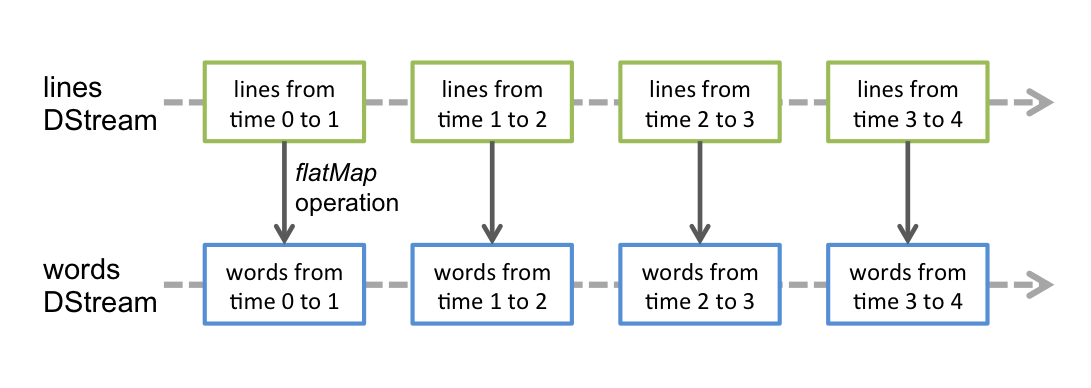
SparkStreaming的高级特性(如map、reduce、join和window)能让用户自由绘制复杂计算逻辑。它们如同魔力之棒,巧妙地转变原始数据,满足精细需求。举例来说,借助flatMap操作,我们可将行流提炼为单词,犹如细水汇入大江。
每条进入DStream的信息均与对应接收器紧密连接,犹如江河护卫,承担着从源头采集数据并存储于Spark内存的关键使命。这就为我们提供了在流处理过程中同步接收和处理多个数据流的可能,如同维护多条江河,确保其顺利汇入大海。
"C:Program FilesJavajdk1.8.0_231binjava.exe"
-------------------------------------------
Time: 1617191345000 ms
-------------------------------------------
-------------------------------------------
Time: 1617191350000 ms
-------------------------------------------
(spark,1)
(java,1)
-------------------------------------------
Time: 1617191355000 ms
-------------------------------------------
(java,2)
-------------------------------------------
Time: 1617191360000 ms
-------------------------------------------
(scala,2)
(java,1)
Process finished with exit code -1
并行接收与处理的秘密
在SparkStreaming技术领域,并发分析及数据处理不仅是技术要求,也是艺术追求。通过精妙地整合多条输入DStream,我们可以将数据洪流引入更为多元且丰富的领域。然而,请务必牢记,每个Spark工作者/执行者均为持续运行的任务,占用着关键的核心资源,犹如河流中的关键节点,以保证数据流动的连续性。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(this.getClass.getName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
为保证SparkStreaming应用高效运行,须精确配置计算资源以满足数据接收及接收器功能要求。此过程如同精雕细琢的园林设计,力求呈现视觉上的协调之美。
本地运行的注意事项
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(1))
在本地区执行Spark流处理应用时,需特别关注以下事项:切勿将”local”或”local[1]”用作主要URL,此举犹如单手接流水,效率极低。反之,建议采用多线程技术,以众志成城之势,确保每一滴水均得到妥善处理。
自定义接收器的魔力
SparkStreaming的关键之处,即利用定制化接收器解析细微数据流。这些特制工具犹如画师所需之颜料,赋予多样化的DStream以独具特色的价值。
结语:数据的未来,由你我共同创造
本篇文章详尽阐述了SparkStreaming在实时大数据处理及深度挖掘上的精细操作方法。每一行代码都象征着我们向数据海洋的深度进发。那么,你是否已经做好准备,以数据流魔法师的身份,利用SparkStreaming构筑属于自己的数据帝国呢?
本文揭示了SparkStreaming的深度魅力,旨在推广其应用,激发大众对其深入理解与灵活运用,共同谱写大数据时代的辉煌篇章。